
Most teams I talk to describe their AI setup as "running multiple agents" when they're actually running one agent with a long list of tools. The distinction sounds semantic until the operation gets complex enough that the single context window starts dropping things: wrong context, missed steps, and outputs that build on assumptions from three tasks back.
Multi-agent AI systems are the architectural answer to that ceiling. Each specialised agent owns one job, scoped to one domain, with one set of tools. An orchestrator routes work between them, maintains state across the pipeline, and keeps the overall goal in view when the individual agents can't see past their own scope.
Where one agent handles tasks in isolation, a coordinated multi-agent system handles entire operations.
For business teams running complex workflows across DevOps, sales ops, customer support, and research, getting that architecture right is the difference between AI that helps with individual steps and AI that runs the whole operation.
TL;DR
- Multi-agent systems split operations across specialised agents, each scoped to one job, coordinated by an orchestrator
- Single agents fail on parallel work, context-heavy tasks, and cross-domain operations, and multi-agent systems solve all three
- Teams run multi-agent ops on platforms like Pazi for DevOps, sales, support, and research workflows
Table of Contents
- What multi-agent AI systems actually are, and why one agent is not enough
- Why single agents hit a ceiling on complex operations
- How multi-agent coordination works: orchestrators, workers, and handoffs
- What operations teams are running on multi-agent systems right now
- How to evaluate whether your operation needs multi-agent architecture
- How to build a multi-agent system, and where Pazi fits
- What to measure once multi-agent systems go live
What multi-agent AI systems actually are, and why one agent is not enough
A multi-agent AI system is a coordination architecture, not a single model with more instructions. It is a set of specialised agents, each scoped to a single function, connected by an orchestrator that routes tasks, manages state, and handles handoffs between them.
The terminology has gotten blurry because "multi-agent" is sometimes used to describe one LLM calling multiple tools, which is just a single agent with an extended toolset and one context window. A genuine multi-agent system has independent agents with distinct roles, separate contexts, and defined interfaces for transferring work between them.
The industry is starting to formalise this. The Agent2Agent (A2A) protocol, backed by Google, IBM Research, LangGraph, and BeeAI, defines how agents discover each other's capabilities, negotiate interaction modalities, and collaborate on long-running tasks without exposing internal state or tools. That is an infrastructure problem being solved at the protocol level, which tells you how seriously the enterprise market is taking multi-agent coordination.
The business case is simpler than the architecture. If a workflow requires a researcher, a writer, a reviewer, and a publisher to operate in sequence or in parallel, that is a multi-agent system. Each specialised agent does one thing well, while the orchestrator makes sure they do it in the right order.
"When you need parallel work, deep specialisation across domains, or context that survives a long task chain, one agent is the wrong architecture."
Why single agents hit a ceiling on complex operations
The ceiling is not a model quality problem but a context and scope problem.
A single agent working through a long task chain accumulates context (instructions, intermediate results, prior steps, tool outputs) until its working memory fills or its coherence degrades. For short, bounded tasks, that is fine. For operations that run across hours, involve dozens of sub-steps, or require deep expertise in multiple domains, single-agent architecture breaks at the seams.
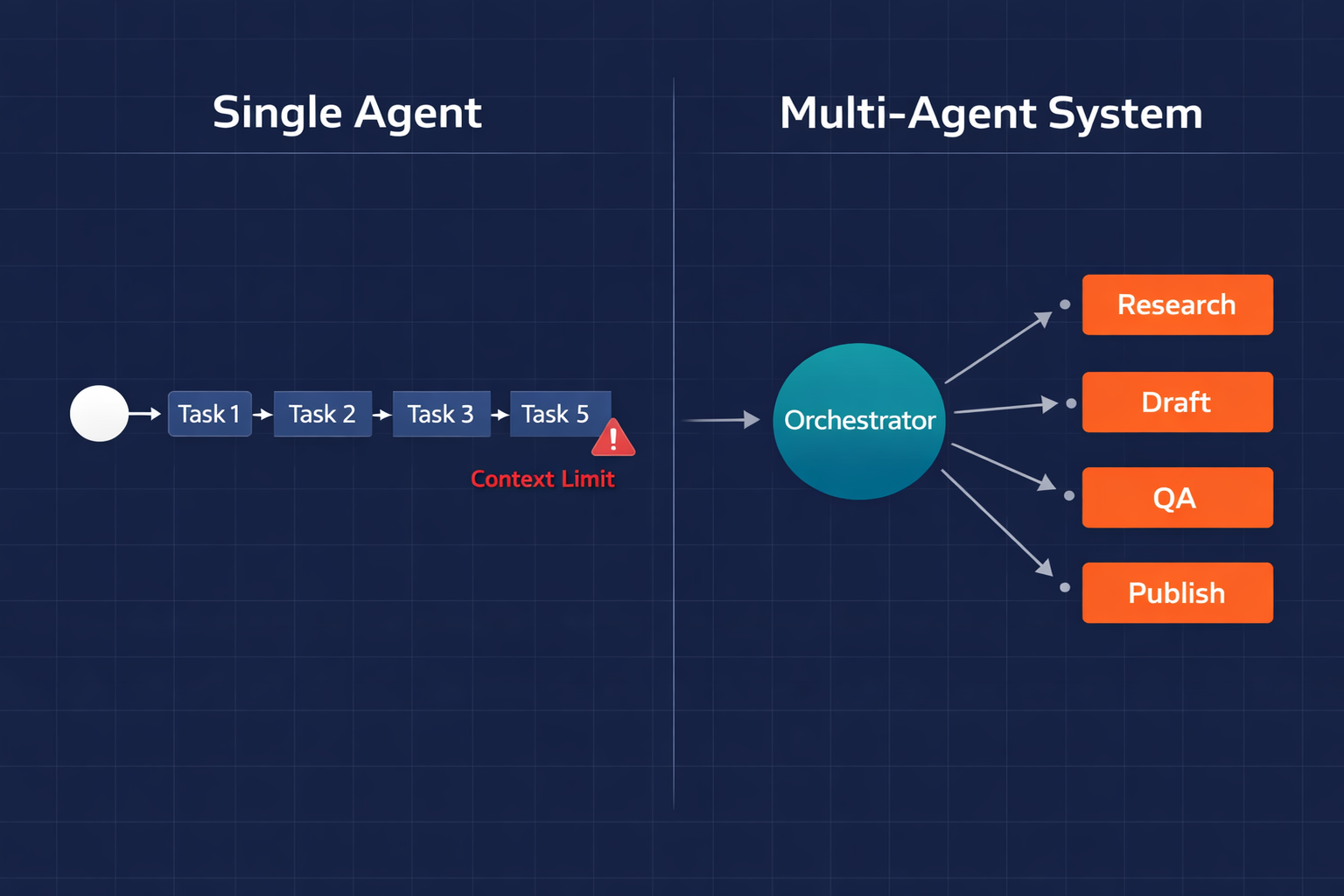
Three failure modes that force the switch
Context collapse is the first. A support triage agent that also drafts resolutions, updates CRM records, escalates to engineering, and generates weekly reports will eventually start confusing tasks or dropping steps. Not because the model is bad, but because no single working memory handles twenty simultaneous concerns well.
Depth vs. breadth paralysis is the second. An agent asked to both understand your codebase deeply and understand your customer tickets deeply will do neither particularly well. Specialisation matters. A DevOps agent that lives inside your monitoring stack and knows Sentry's error taxonomy will catch failure patterns that a generalist agent misses.
Parallelisation failure is the third. If an operation has five independent workstreams (market analysis, competitor tracking, content planning, campaign execution, and results reporting), a single agent runs them sequentially. A multi-agent system runs them in parallel, which is why sequential processing is the bottleneck and parallel coordination is the lever.
For the full decision framework on when specialisation is worth the architectural cost, see Specialist vs. Generalist Agents: When One Isn't Enough.
How multi-agent coordination works: orchestrators, workers, and handoffs
Every multi-agent system is built on three structural components, each with a distinct role, and that simplicity is intentional.
Worker agents are scoped to a single function. A research agent. A drafting agent. A QA agent. A publishing agent. Each has its own context, tools, and success criteria. It does not know or care about the larger pipeline; its job is to receive a task, execute it, and return a result.
The orchestrator knows the goal. It breaks complex tasks into steps, assigns steps to worker agents, handles results, and decides what happens next. It is the only component with a system-wide view. A well-designed orchestrator is what separates a loose collection of agents from an actual operational system.
Handoff protocols are how state survives the transfers. CrewAI (the leading open-source framework for orchestrating autonomous AI agents, with 100,000+ developers certified through community courses) built its core around Crews (autonomous teams that collaborate on tasks) and Flows (event-driven structured workflows) precisely because handoff design is where most multi-agent implementations fail.
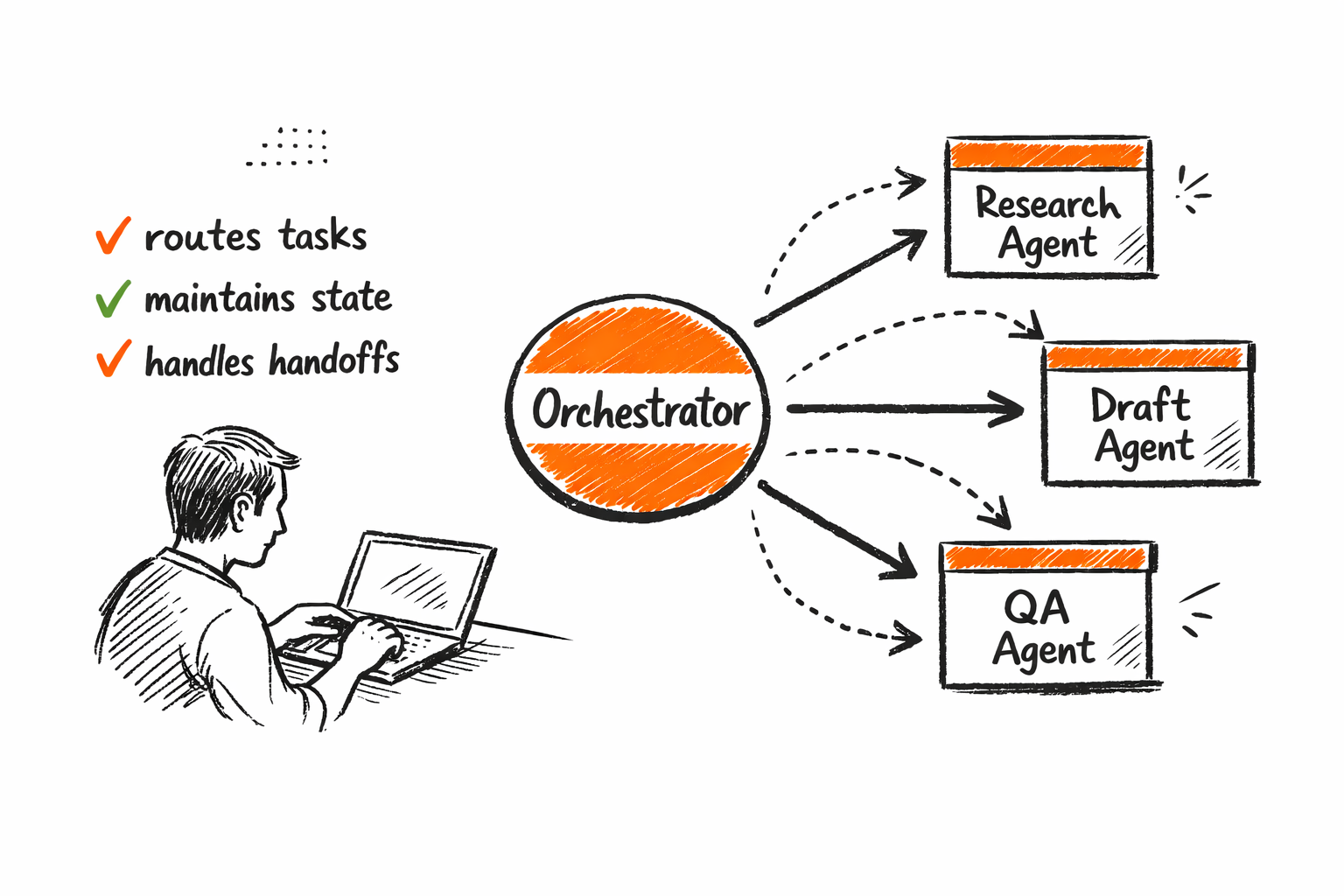
How context passes between agents
The most common multi-agent failure is context loss at the boundary. An orchestrator that passes a task ID without context forces the receiving agent to start from scratch. Good multi-agent design is explicit about what gets passed: which prior results, which constraints, and which success criteria.
Microsoft's Agent Framework 1.0 (the enterprise-ready successor to AutoGen) addresses this directly. It provides enterprise-grade multi-agent orchestration with cross-runtime interoperability via A2A and MCP, which means context can survive handoffs across agents running on different runtimes or from different vendors. For enterprise teams assembling multi-vendor pipelines, that interoperability is a real infrastructure gain.
The orchestrator is a router, not a manager
One conceptual mistake teams make is treating the orchestrator like a quality supervisor, when its actual job is routing and sequencing; the quality check belongs to each worker agent, and if the orchestrator is running QA, the agent design is wrong upstream.
"Context loss at the boundary is the most common multi-agent failure. It is an architecture problem, not a model problem."
What operations teams are running on multi-agent systems right now
Abstract architecture is fine. What does this look like in production?

DevOps and SRE
A DevOps multi-agent system typically runs at least four agents: a monitoring agent watching Sentry and Datadog, a log-analysis agent parsing raw traces, a root-cause agent cross-referencing similar incidents in Linear, and a response agent drafting the incident report and routing escalations to Slack. The orchestrator fires when monitoring detects an anomaly and coordinates the rest in parallel.
In teams that have deployed this coordination pattern, incident response cycles that previously required 30-60 minutes of cross-system manual triage have compressed to under 10 minutes, with the SRE reviewing a prepared summary rather than assembling one from scratch. See AI agent workflows for operations for more on how this orchestration pattern scales. For a step-by-step implementation, see I built an autonomous dev team with 3 AI agents, which shows how three agents take a Linear ticket all the way to a pull request.
Sales operations
A sales ops system might coordinate a prospecting agent that finds and qualifies leads from defined signals, an enrichment agent pulling company data from Apollo and LinkedIn, a personalisation agent drafting outreach based on enriched context, and a tracking agent logging every interaction to HubSpot without human input. The orchestrator manages timing, with enrichment running before personalisation and tracking firing after every send.
A single agent running all four steps sequentially is rate-limited by context switching and sequential IO. Multi-agent coordination, running enrichment and prospecting in parallel, can double or triple throughput for the same wall-clock time, depending on data source latency.
Customer support pipelines
A multi-agent support system separates triage, resolution drafting, escalation, and follow-up into distinct agents. The triage agent reads the ticket and routes it; once routed, the resolution agent drafts based on the knowledge base. A QA agent checks the draft against policy before it goes out. The orchestrator ensures high-severity tickets bypass the drafting queue and go directly to a human escalation channel in Intercom.
That structure is impossible with one agent simultaneously triaging, drafting, QA-checking, and escalating, because the context gets too heavy and the prioritisation logic gets too entangled. Find more examples across team types in AI agent use cases for operations teams.
Research and content operations
Content operations teams have found that a multi-agent approach (separate research, outline, drafting, editing, and publishing agents) produces better output faster than a single "write me a post" agent. Each agent's narrow scope is what produces better depth, since the research agent goes deep, the outlining agent structures, and the drafting agent writes to that structure.
How to evaluate whether your operation needs multi-agent architecture
Not every operation needs multi-agent coordination. The overhead of orchestration design is real, and for simple, single-step tasks, one agent is the right tool.
Four questions that reveal readiness
The first is whether the operation has distinct phases that require different expertise. If your workflow naturally splits into research → analysis → writing → review → publishing, that is a multi-agent candidate because each phase has different success criteria and different tool requirements.
The second is whether the operation gets stuck waiting for sequential processing. If tasks are blocked on prior steps when they could run in parallel, you are leaving speed on the table. Multi-agent parallelism solves sequential bottlenecks directly.
The third is whether a single agent's context fills before the task completes. If you notice quality degradation mid-task, with the agent "forgetting" context it held earlier and making contradictory decisions, which is the hallmark of context collapse.
The fourth is whether the operation spans multiple systems that each require genuine specialisation. A single agent that needs to deeply understand Sentry's error taxonomy, GitHub's PR workflow, Linear's project schema, and Slack's message formatting is asking too much of one context window. That is a specialist workload, not a generalist one. See what makes an AI agent truly autonomous for a deeper look at autonomy thresholds.
Red flags that multi-agent is not the right move yet
- The task is single-step. "Summarise this document" needs one agent.
- The orchestration overhead exceeds the value. A three-agent system for a 30-second task is premature complexity.
- The team has no observability tooling. Multi-agent systems need monitoring. If you cannot see what each agent is doing, debugging failures is intractable.
- The handoff design is unclear. If you cannot articulate what data passes between each agent, the system will fail at the boundaries.
The right question is not "can we build a multi-agent system?" because almost any operation can be broken into agent roles; the better question is whether the operation's complexity justifies the architecture.
How to build a multi-agent system, and where Pazi fits
Building a multi-agent system is a workflow design problem, not a model selection problem, because the architecture decisions matter more than the LLM choice.
Step 1: Map the operation into distinct jobs
Start on a whiteboard, not in code. Break the target operation into discrete jobs, each with a clear input, a clear output, and a clear success criterion. Each discrete job is a candidate agent. If two jobs share context so heavily that separating them loses information, they belong in the same agent.
Step 2: Design the orchestrator logic first
Before building any worker agent, define the orchestrator's routing logic. What triggers the system? What sequence do agents run in? What happens when an agent fails or returns an ambiguous result? The orchestrator is the hardest component to retrofit, so design it first.
Step 3: Define handoff contracts
Write down what data passes between every pair of adjacent agents: the fields, the format, and how failures are signalled. Treat it as a real interface specification. Because it is.
Step 4: Run the single-agent path first
Before building the multi-agent version, run the full operation with one capable agent to surface where it breaks down. Document what it forgets, what it conflates, and what it drops, because those failure points are your agent boundaries.
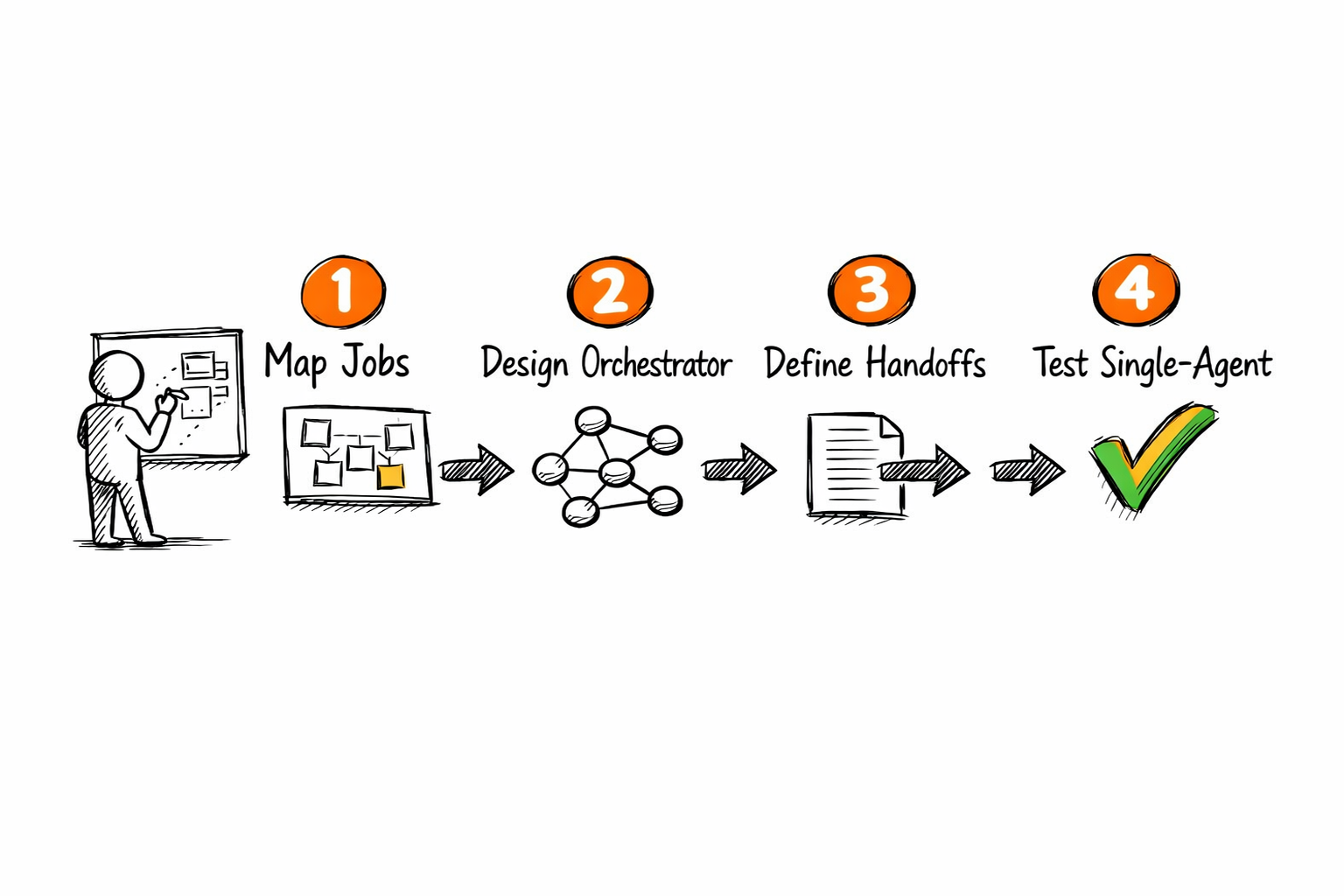
Where Pazi fits
Teams that hit the single-agent ceiling move to agent platforms like Pazi, built for ops work that requires judgment across domains, not just execution within one. Pazi's architecture supports multi-agent coordination natively, with orchestrator design, worker agent scoping, tool assignment, and handoff configuration as first-class workflow concepts rather than framework workarounds.
The build-vs-buy question matters here because framework-level tools like CrewAI and AutoGen give you the orchestration primitives, while platform-level tools like Pazi give you the operational layer (monitoring, handoff visibility, credential management, agent permissions, and rollback) that production deployments actually need. For teams deploying at enterprise scale, the enterprise AI agent platform evaluation guide covers the full picture.
What to measure once multi-agent systems go live
A multi-agent system in production is a set of distributed processes, which means measuring it requires distributed instrumentation.
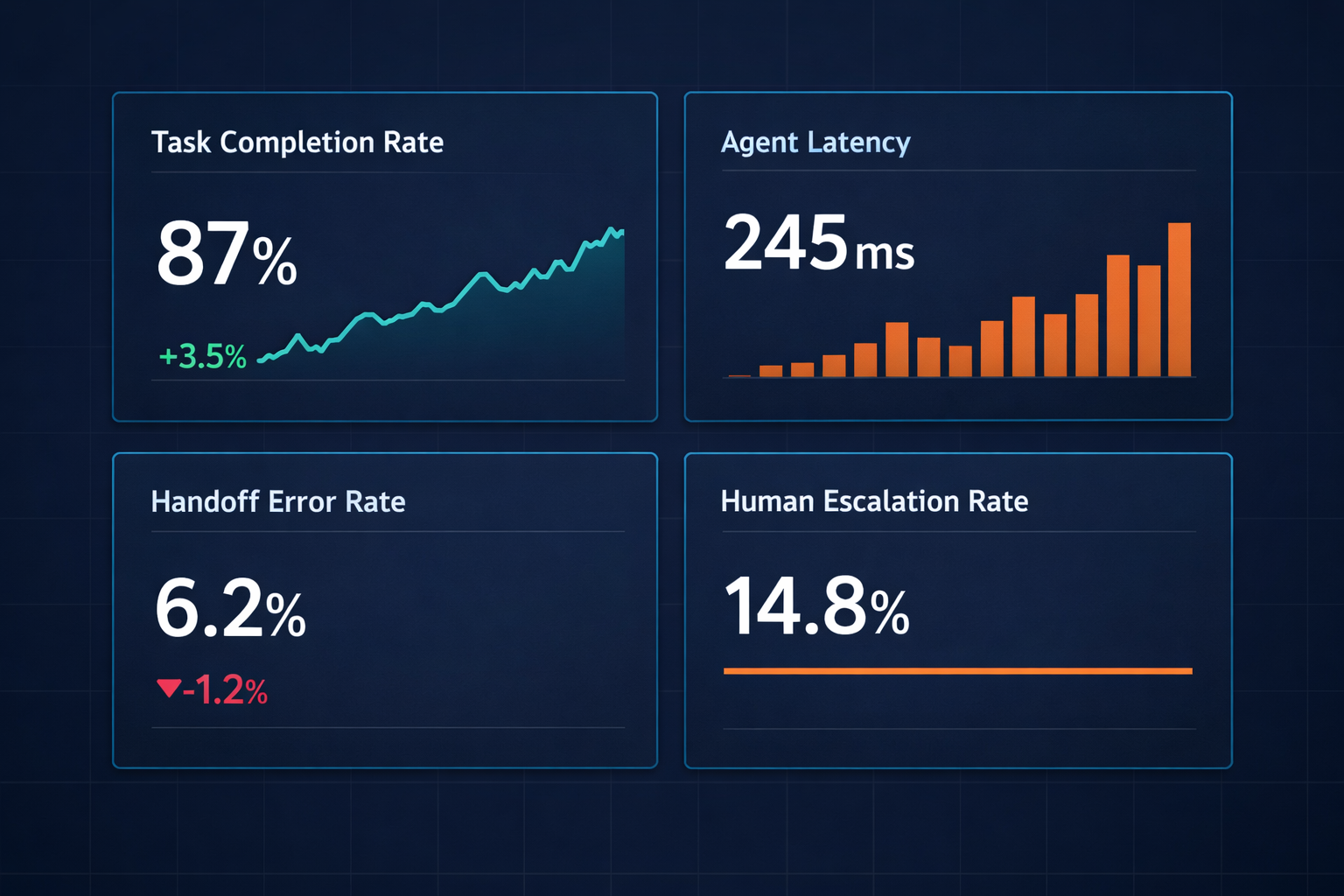
Agent-level metrics
Task completion rate measures the percentage of tasks each worker agent completes without escalation or failure. If one agent completes 60% of tasks while others complete 90%, the problem is in that agent's scope, its tool access, or the quality of its handoff inputs.
Agent latency tracks how long each agent takes to process a task. Latency outliers identify bottlenecks in the pipeline, and if the enrichment agent takes 10x longer than the others, the whole pipeline waits on it.
Context utilisation rate shows how close to the context ceiling each agent operates. Consistently running at 80%+ signals that the agent's scope is too broad for one context window.
Pipeline-level metrics
End-to-end task completion time is the total time from orchestrator trigger to final output. Compare it against the pre-multi-agent baseline, because if the pipeline is slower than what a single agent was doing, the orchestration overhead is too high.
Handoff error rate measures the percentage of inter-agent handoffs that result in context loss, malformed inputs, or failed task starts. High handoff error rates are architectural problems, not model problems.
Human escalation rate tracks how often the pipeline escalates to a human. A rate above 20% typically signals that agent scoping is off or that the orchestrator's routing logic has gaps.
Business-level metrics
Business-level metrics matter more than the technical ones. If the DevOps multi-agent system cuts incident response time from 45 minutes to 4 minutes, that is the number. If the sales ops system increases qualified outreach volume by 3x with the same headcount, that is the number.
Technical metrics track the infrastructure, while business metrics are the reason you built the system.
"Multi-agent systems earn their ROI at the business level, counting incident minutes saved, leads qualified per hour, and tickets resolved per shift. Measure there first."
The measurement gap is where many multi-agent deployments fail to prove ROI. Not because the system is not working, but because the team never defined what "working" looked like before they started. Define your business-level success metrics before the first agent goes live.
Further reading
- Specialist vs. Generalist Agents: When One Isn't Enough: the decision framework for when to split a generalist agent into specialised roles, covering context contamination, depth trade-offs, and consolidation risk
- I built an autonomous dev team with 3 AI agents: a concrete multi-agent implementation that takes a Linear ticket all the way to a pull request
- What makes an AI agent truly autonomous: the autonomy foundations each worker agent needs before it can function reliably in a multi-agent pipeline
Single Agent vs Multi-Agent System: Quick Reference
| Capability | Single Agent | Multi-Agent System | Best For |
|---|---|---|---|
| Parallel task execution | Sequential only | Native parallel coordination | Operations with independent workstreams |
| Deep domain specialisation | Limited (generalist context) | Each agent scoped to one domain | DevOps, sales ops, content ops |
| Long-running operations | Context collapse risk | Context isolated per agent | Multi-hour workflows, complex pipelines |
| Simple bounded tasks | Optimal, no overhead | Overkill | Single-step automations |
| Observability | Easier to monitor | Requires distributed instrumentation | Depends on team maturity |
| Setup complexity | Low | High, with orchestration design required | Teams with clear workflow boundaries |
| Cross-system coordination | One tool context | Specialised tool access per agent | Operations spanning multiple platforms |
Ready to run complex operations at scale?
Pazi is a platform that runs multi-agent operations natively, connecting orchestrators, worker agents, and handoff contracts in a single workspace built for the kind of ops work that requires judgment across domains.
Multi-agent systems are not the answer to every AI ops problem, because for simple, bounded tasks, a single agent is faster and easier to maintain. But for operations that require parallel work, deep specialisation, or long task chains across multiple systems, single-agent architecture has a real ceiling.
The businesses getting the most out of AI in 2026 are running coordinated pipelines where Sentry-watching, ticket-triaging, lead-enriching, and report-generating agents work in concert under an orchestrator that never sleeps.
If your operations team is ready to move beyond that ceiling, start with one operation on Pazi, map the jobs, design the orchestrator, and measure the outcome. That is how multi-agent architecture earns its keep, in the metrics that matter to your business.



