
The default architecture on every agent platform is a single instance that does everything. One system prompt carrying every directive, one shared toolbox, one conversation history accumulating context from every function. You start with customer support, add content drafting, bolt on deployment monitoring, and before long the same agent covers six distinct jobs.
Nothing breaks outright. Every task completes and every output passes a quick read. But compare the marketing copy from three months ago against what the system produces today, and something has flattened. The support responses lost precision somewhere around the time you added competitor tracking, and the code reviews miss edge cases they used to catch. Nobody flagged a problem because there was never a single moment where things went wrong.
The generalist-vs-specialist question is the most consequential architectural decision in agent design that most teams aren’t explicitly making.
How generalist setups degrade
The degradation follows predictable patterns rooted in how language models process instructions.
Context window dilution
Every LLM call operates within a fixed token budget. Pack support rules, copywriting guidelines, deployment runbooks, and competitor tracking directives into one prompt, and all of them compete for the model’s attention at once.
Anthropic’s engineering team observed that “for complex tasks with multiple considerations, LLMs generally perform better when each consideration is handled by a separate LLM call, allowing focused attention on each specific aspect.” LangChain’s multi-agent documentation reached a parallel conclusion: “An agent is more likely to succeed on a focused task than if it has to select from dozens of tools.”
The model doesn’t skip the rules it doesn’t need right now. Your monitoring runbooks influence output weighting while the system drafts a blog introduction, subtly skewing word selection and reasoning even when completely irrelevant. More guidelines loaded means proportionally thicker noise on every assignment.
The difference becomes clear when you compare how each architecture allocates its context window:
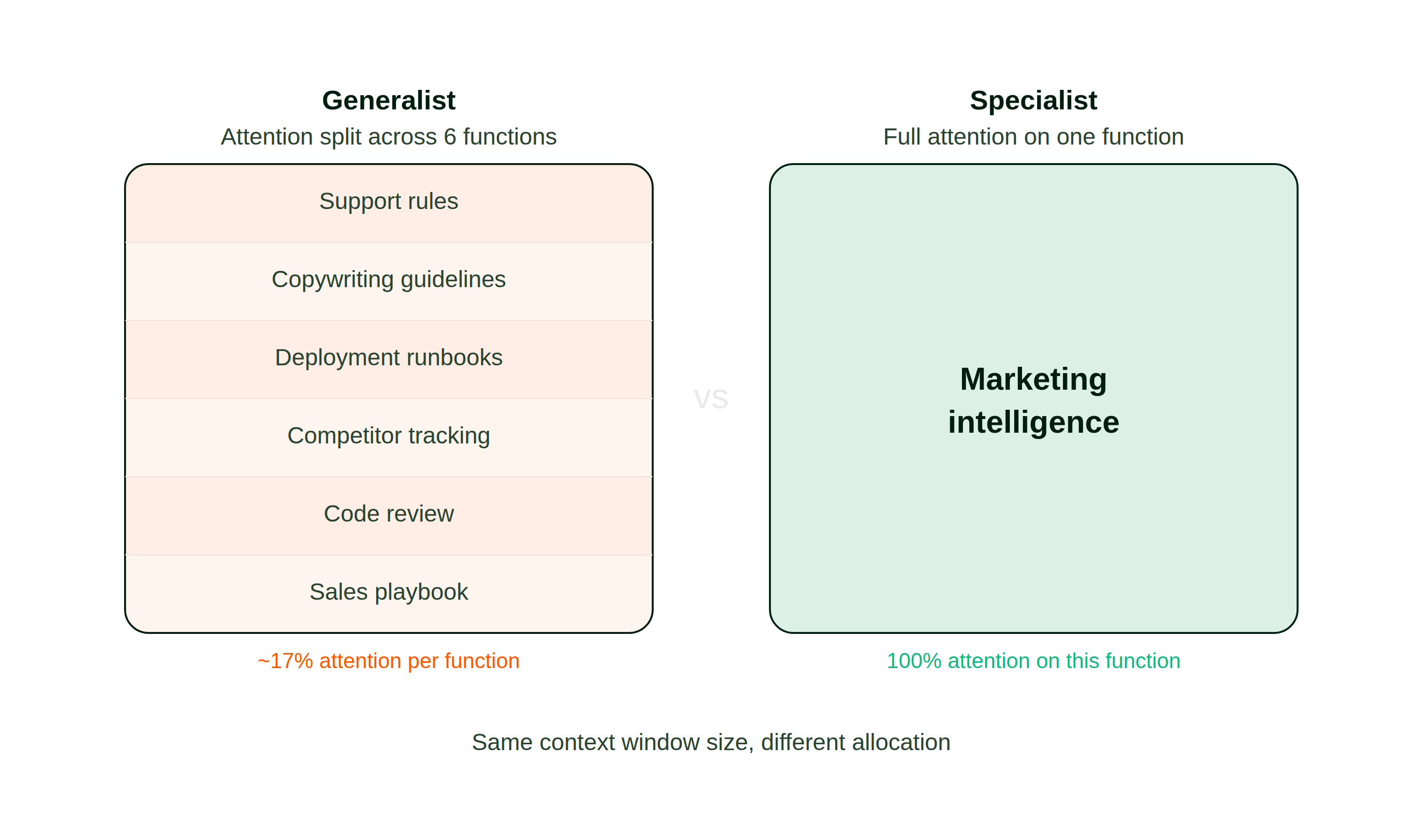
The published research on long-context retrieval reinforces this. Models concentrate attention at the beginning and end of large inputs while material in the middle receives diminished focus. In a packed system prompt, the instructions that matter most for the current task may sit in exactly the zone where the model pays the least attention.
Instruction collision
Different functions carry contradictory behavioral rules. A support persona should be empathetic and conciliatory. A code reviewer needs bluntness and precision. A sales voice needs confidence and urgency. Put those behavioral blueprints in a single prompt and the model resolves contradictions by blending, producing output that hits the right register for none of them.
This compounds with overloaded vocabulary. If your prompt defines “performance” in an infrastructure sense (latency, uptime) and simultaneously in a marketing sense (click-through, conversion), the model disambiguates on every encounter. Sometimes correctly. Sometimes your quarterly campaign summary includes server response figures because the system couldn’t parse which meaning you intended.
Tool selection overhead
When you mount tools for multiple functions onto one runtime, the selection problem multiplies. An agent with database queries, an email dispatcher, a deployment trigger, and a social scheduler evaluates every option on every action cycle. More available tools means higher odds of invoking the wrong one, plus additional reasoning burned on selection rather than execution.
Anthropic flagged this in their routing pattern documentation: “Without this workflow [routing to specialized followup tasks], optimizing for one kind of input can hurt performance on other inputs.”
Memory pollution
Agents that retain conversation history across functions accumulate cross-contamination over time. Debugging artifacts bleed into the next copywriting session, and customer conversation details surface in internal documentation. Every prior exchange adds noise to subsequent interactions, compounding until the memory store creates more confusion than clarity.
What the tax looks like
Each failure mode compounds into concrete costs that are easy to miss because nothing obviously breaks.
Shallower analysis. A generalist loaded with coding review, support playbooks, and competitive research tools produces surface-level competitor briefs. A dedicated instance carrying only intelligence-gathering tools and analytical context goes deeper because its entire token budget serves one objective.
Inconsistent voice. Copywriting from a multi-role agent carries tonal artifacts from its other behavioral modes. The register drifts between assignments because the master prompt pulls stylistic tendencies in competing directions.
Slower throughput. Additional directives and mounted tools translate to more tokens processed per call, more reasoning spent on tool selection, and longer turnaround per request. On recurring pipelines, this latency accumulates into hours of lost output over a week.
Harder debugging. A flawed result from a generalist could originate in any loaded directive, any mounted tool, or any cached history fragment, making root-cause analysis painful. With a narrowly scoped agent, the debugging surface shrinks to one function and one set of tools.
Here is what the two architectures look like side by side:
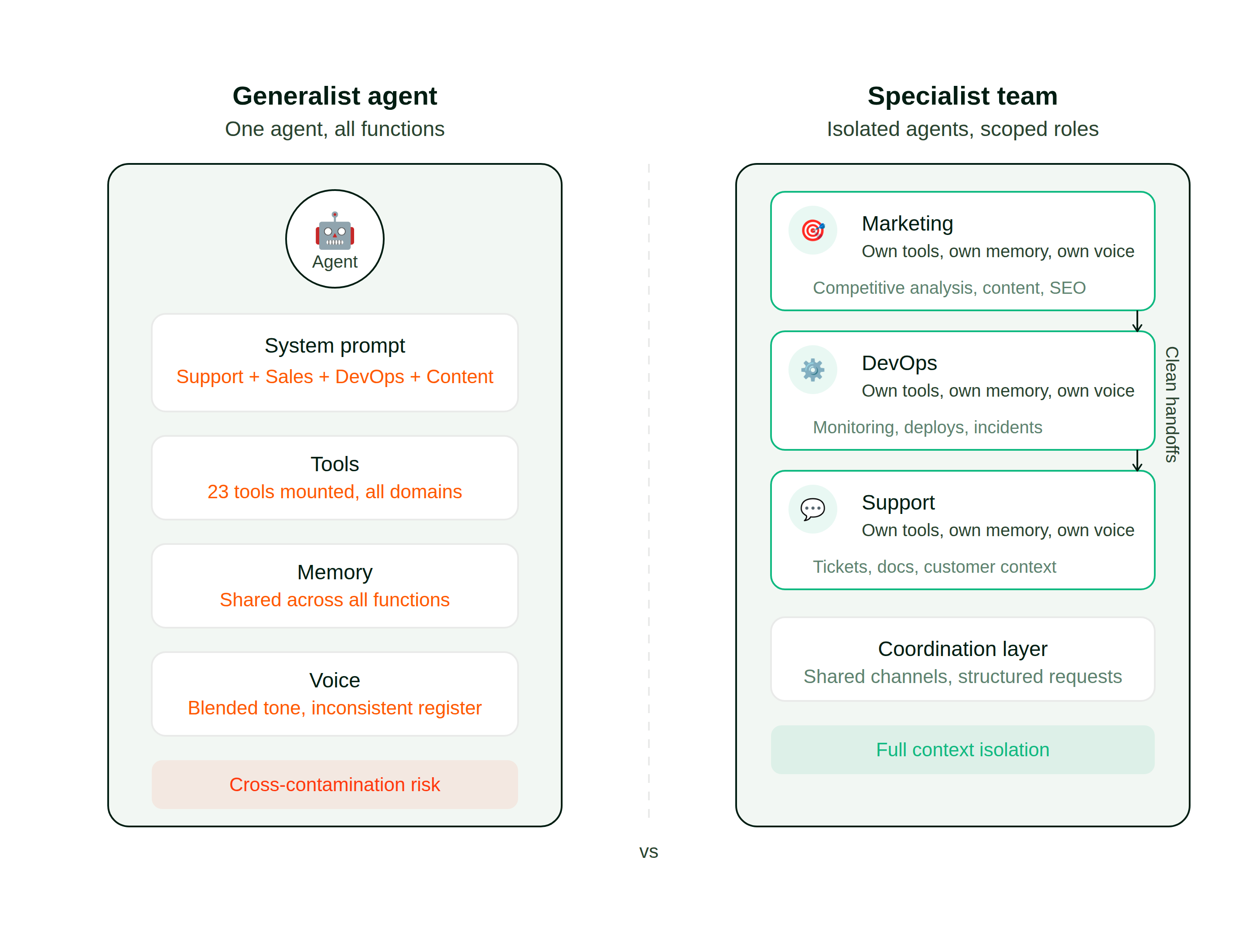
None of these failures are dramatic, which is precisely the problem. They’re all “acceptable,” and organizations tolerate them for months before somebody questions whether the underlying architecture is the limiting factor.
When to specialize, when to stay consolidated
Not every workflow needs multiple agents. Anthropic’s foundational guidance on building agents is to “find the simplest solution possible, and only increase complexity when needed.” Specialist setups carry genuine overhead, and for certain scenarios a single well-prompted agent remains the better path.
The following decision flow captures the evaluation sequence:
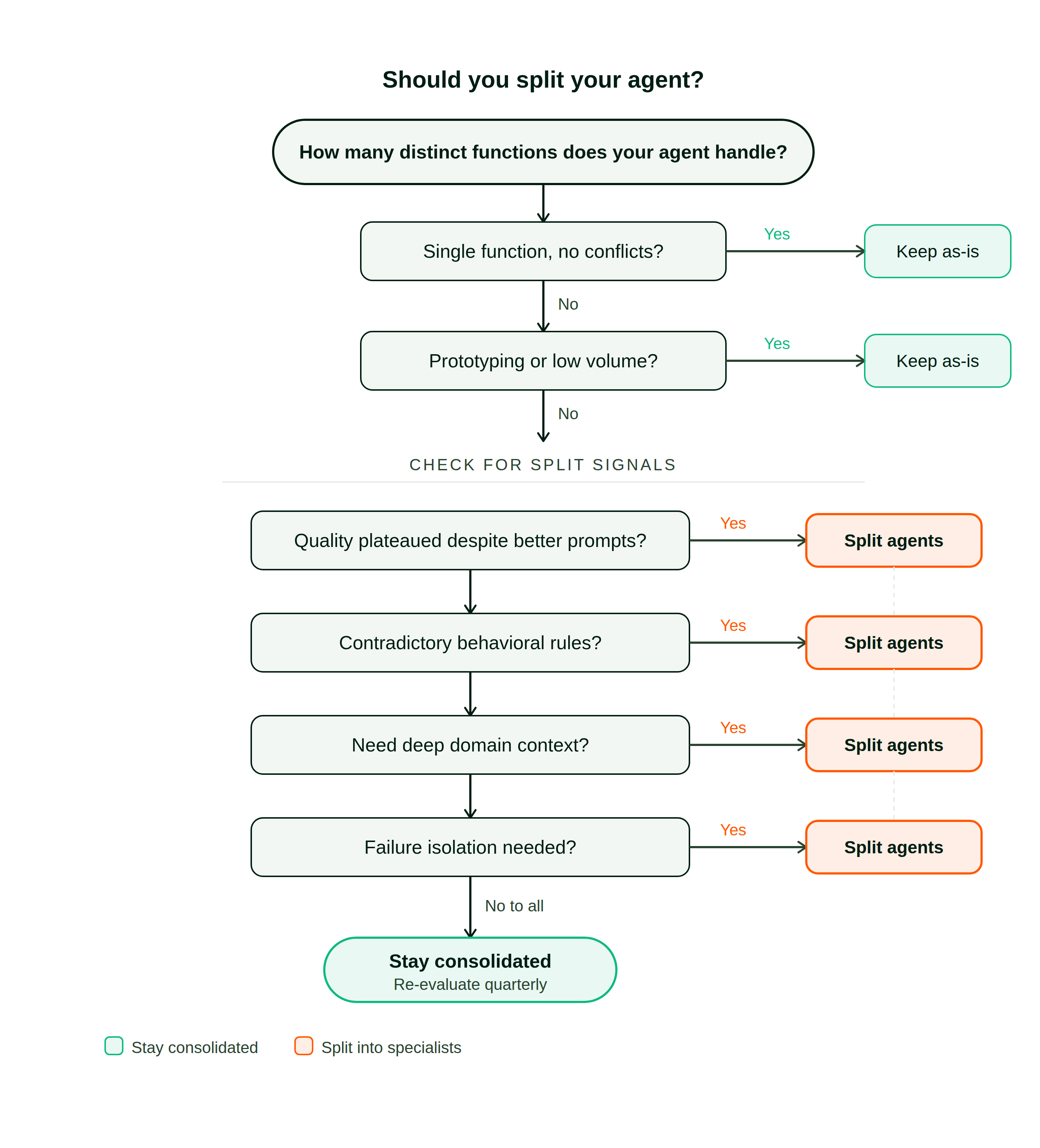
Stay consolidated when
The strongest case for a single agent is when it serves a single function with no conflicting behavioral rules. If it exclusively handles support conversations, or exclusively reviews pull requests, or exclusively writes content, there’s no cross-contamination to address. The context window is already tight and splitting would add coordination cost for zero quality gain.
Consolidation also makes sense during prototyping, when you need fast iteration. A consolidated setup lets you add a tool, test a use case, and discover what works before hardening into a permanent architecture. Premature decomposition locks you into structural commitments you don’t have data to validate.
Finally, if request volume is low and the system processes only a handful of tasks daily, the fidelity gap between consolidated and specialized may not justify the configuration burden.
Split when
The clearest signal is output quality plateauing despite better prompts. If adding capabilities no longer improves any of them, and your copywriting was sharper before you bolted on infrastructure monitoring and code review, the token budget is likely saturated.
Contradictory behavioral rules are another strong trigger. Support and sales differ in register, engineering and marketing differ in vocabulary, and putting those contradictions in one prompt regresses the output toward a compromise that serves none of them well.
Split when you need deep domain context that would crowd out everything else. A purpose-built SEO agent can hold keyword research, competitor positioning matrices, and algorithm tracking that would be pure noise in a generalized prompt. A dedicated DevOps agent can carry dense runbooks and monitoring configurations without diluting your marketing agent’s creative output.
And split when failures in one function shouldn’t cascade into another. If a broken deployment script should never contaminate a customer-facing response, structural isolation provides real safety boundaries that prompt engineering alone cannot guarantee.
Warning signs to track
Growing latency at constant complexity points toward a bloating instruction payload. Engineering jargon leaking into customer messages is direct evidence of behavioral collision. The agent citing infrastructure data in a marketing brief, or making tool calls that don’t match the current task, signals that the context window is overloaded.
Two or more of those patterns in the same quarter means the consolidated setup has likely outgrown its design.
How specialist architectures work
The foundational principle is isolation. Each agent runs in its own workspace with its own behavioral prompt, its own tools, and its own persistent memory. A marketing agent carries competitive analysis tools and campaign data while a DevOps agent carries monitoring dashboards and deployment orchestration. They share no state between them.
This maps directly to every failure mode examined above. Context dilution disappears because each agent only loads its own function’s material. Contradictory behavioral rules can’t collide when they never share a prompt. Tool selection simplifies because every mounted capability is relevant to the active task, and memory stays clean because each agent’s history concerns exactly one discipline.
Coordination between specialists
Isolation resolves contamination but introduces a coordination challenge. Several patterns have emerged, each with distinct trade-offs.
Here is how specialist agents coordinate through a shared communication layer:
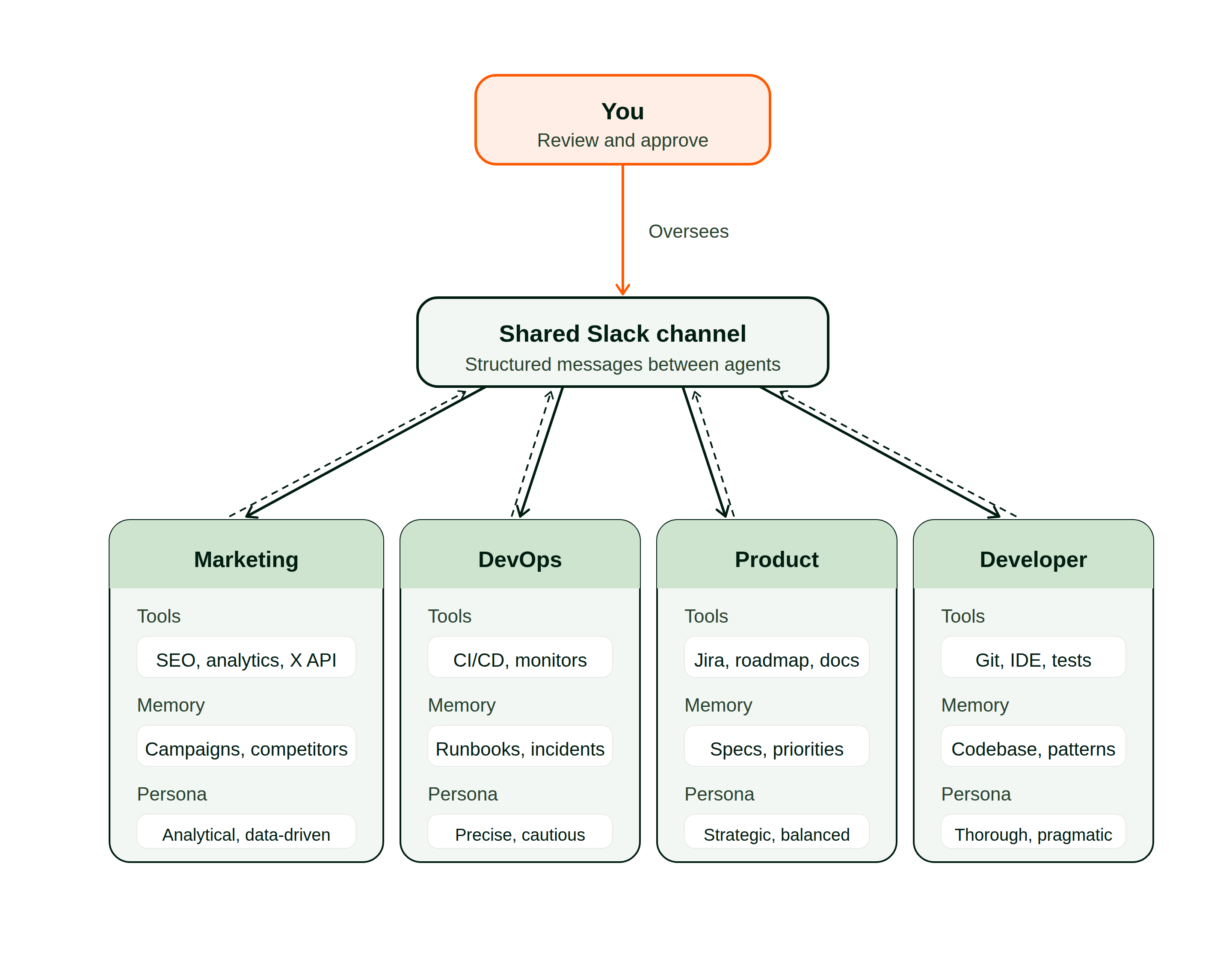
Channel-based messaging. Agents communicate through a shared surface like Slack or a message broker. If one needs another’s expertise, it posts a structured request and waits for a response. This mirrors how human organizations coordinate: domain experts in shared channels, requesting help from whoever holds the relevant knowledge.
Centralized orchestration. A coordinator inspects incoming requests and routes them to the appropriate handler. Anthropic catalogs this as the “orchestrator-workers” pattern, suited for “complex tasks where you can’t predict the subtasks needed.” The orchestrator assigns work but doesn’t execute it.
Hierarchical delegation. Specialized workers operate beneath supervisors, who report to higher-level coordinators. This scales to large topologies but adds latency through the coordination layers.
No single pattern dominates. Channel-based messaging is simplest and cleanest in boundary enforcement. Orchestration excels at dynamic routing but introduces a bottleneck at the coordinator. Hierarchical structures scale but impose latency. The right choice depends on your specific constraints and workflow shapes.
A concrete example: picture a team with separate marketing, development, and product agents. The marketing agent flags a competitor launching a feature that changes positioning. It doesn’t update the roadmap itself. It posts a structured alert to a shared channel with an impact assessment. The product agent picks up that alert, evaluates it against roadmap priorities and engineering bandwidth, and delegates implementation work to the dev agent. Each handoff is clean because the receiving agent contributes its own specialized context instead of inheriting the sender’s history.
The human’s role
In a specialist setup, each agent handles the repeatable analytical and operational work within its function. You review the outputs, approve actions, and make the cross-functional judgment calls that require business context the agents don’t have. The marketing agent runs the competitive scan; you decide what to do about what it finds. The dev agent writes the fix and opens a PR; you review it. The agents handle execution so you can focus on the decisions that actually need your judgment.
What specialization costs
Running five specialists instead of one generalist means five configurations to maintain, five sets of monitoring, and communication pathways between them that need error handling for stalled handoffs. Policy updates (safety rules, formatting standards, communication norms) must propagate across every instance individually. Cross-function requests that a consolidated setup handles in one turn may require two or three sequential handoffs, each adding processing delay.
This overhead is real. If your complete prompt fits within a few hundred lines and spans fewer than three distinct disciplines, consolidation is likely the simpler and better path. Certain directives legitimately belong everywhere (safety rules, formatting standards, organizational communication norms), and without a shared inheritance mechanism you’ll copy them across every instance or engineer a templating system to manage them.
Specialization pays off when the quality degradation from overloading one agent clearly exceeds the coordination cost of running several. A well-prompted consolidated agent will outperform a poorly orchestrated team of specialists every time, so the question is always whether your contamination problem is worse than your coordination overhead.
Where the industry is heading
The major agent frameworks are already organized around specialist patterns. LangGraph offers primitives for inter-agent communication and supervisory hierarchies. Anthropic’s published guidance catalogs orchestrator-worker and capability-routing patterns that assume focused handlers as the fundamental building blocks. CrewAI, AutoGen, and similar projects are built entirely around role-designated agents cooperating on shared objectives.
The architectural direction is clear. What lags behind is the tooling to make it practical. Standing up a team of specialist agents today requires significant configuration: separate prompts, separate tool sets, separate storage, plus the coordination layer connecting them. Whoever makes that setup fast and painless will remove the last real barrier to adoption.
That’s the problem we’re working on at Pazi. You pick a role, connect your tools, and the agent launches in its own isolated workspace, coordinating with the rest of your team through Slack. We run this setup internally with separate agents for marketing intelligence, competitive analysis, content production, and development, each with scoped tools and persistent memory. The difference between that and the single-agent approach we started with is what convinced us to build the entire product around specialist architecture.
The pattern works regardless of which platform implements it. The decision framework, warning signs, and evaluation criteria in this post apply whether you build on raw APIs, adopt a framework like LangGraph, or use a managed platform. The important thing is making the architectural choice deliberately instead of by default.
For a complete guide to building and running multi-agent systems across business operations, see Multi-Agent AI Systems for Business: How to Run Complex Operations Across Multiple Agents.
Built at Pazi, powered by OpenClaw.



