Revenue operations automation, applied to the wrong layer first, doesn't give RevOps teams their time back. It gives them wrong data, faster. The weekly forecast that still needs manual adjustment before it goes to leadership, the pipeline report that still takes half a day to prepare, the CRM that is always one sprint behind: these aren't signs that automation failed. They are signs it started in the wrong place.
The RevOps function has a dependency structure. CRM data quality feeds pipeline accuracy. Pipeline accuracy feeds forecast reliability. Forecast reliability feeds quota and territory visibility. Automate the outputs before you automate the foundation and you're printing dashboards built on errors. This guide walks through the right sequence: which layer to automate first, what agents own at each layer, and how to wire them into the tools your RevOps team already uses.
Table of Contents
- The Coordination Tax in RevOps
- Get the Sequence Wrong and Automation Amplifies the Problem
- The Foundation Layer — CRM and Pipeline Hygiene
- The Middle Layer — Pipeline Review and Forecast Automation
- The Output Layer — Quota Tracking, Territory Visibility, and Deal Desk
- Wiring the Agent to Your RevOps Stack
- The Metrics That Tell You the Sequence Is Working
The Coordination Tax in RevOps
Revenue operations is, by design, a coordination-heavy function. It owns the plumbing between sales, marketing, and finance: pipeline visibility, sales forecasting, CRM hygiene, territory planning, quota tracking, deal approval workflows, and revenue reporting. The function exists to make revenue predictable by maintaining the data infrastructure that every other revenue team depends on.
When that coordination layer runs on human attention, the cost compounds in predictable ways. A pipeline report assembled by hand today is already partially wrong tomorrow. A forecast adjusted manually before the board meeting is a forecast the RevOps manager didn't trust enough to leave untouched. A CRM cleaned in the sprint before a board review is clean for one sprint and messy for the other eleven weeks of the quarter.
According to Salesforce's 2025 State of Sales report, nine in 10 sales teams already use AI agents or expect to within two years. The RevOps function, which is responsible for the data infrastructure those agents read from, is where that investment either compounds or collapses. For a look at how the same repeatable-versus-judgment layer logic applies to customer-facing teams, the account management automation framework covers the same structural principle applied to the AM role.
The RevOps function exists to make revenue predictable. Manual infrastructure means revenue can only be reported, never predicted.
Get the Sequence Wrong and Automation Amplifies the Problem
RevOps data has a dependency structure. Each layer builds on the accuracy of the layer below it. CRM hygiene is the foundation. Pipeline stage accuracy builds on it. Forecast confidence builds on pipeline accuracy. Deal desk efficiency and territory reporting are outputs of the whole chain.

When teams automate the output layer first, they automate whatever is currently in the data, including the errors. A beautifully formatted pipeline dashboard built on manually maintained data is not an insight tool. It is a fast path to a wrong number that arrives faster than a human could have produced it.
HubSpot's 2025 State of Sales research finds that 40 percent of salespeople now use AI for data analysis and forecasting, and 32 percent automate note-taking, scheduling, and CRM updates. That adoption wave is reaching RevOps teams, but adoption without sequencing means the automation lands on whatever is already in the CRM, including the fields no one updated, the deals with wrong stage dates, and the contacts whose owners left six months ago.
| Layer | What breaks without it | What agents automate at this layer |
|---|---|---|
| CRM data quality | All downstream data is wrong at the source | Field validation, contact enrichment, deduplication, stale deal flagging |
| Pipeline stage accuracy | Forecast is working from wrong inputs | Stage hygiene enforcement, activity tracking, next-step validation |
| Forecast confidence | Quota and territory planning unreliable | Forecast deviation alerts, weekly pipeline review prep, call-data sync |
| Quota and territory visibility | Deal desk and leadership operating on bad signals | Quota attainment reporting, territory gap alerts, performance digests |
| Deal desk efficiency | Revenue leaks through slow approval loops | Threshold-triggered routing, approval workflows, deal desk cycle tracking |
Automation doesn't fix dirty data. It moves dirty data faster.
That's true when automation lands on the output layer. At the foundation layer, the agent's entire job is to fix the data: validating fields, merging duplicates, enriching records, flagging what's stale. The sequence matters because the first two layers are corrective; the later ones are only additive.
The Foundation Layer — CRM and Pipeline Hygiene
The foundation layer is where most RevOps automation should start and where almost no one starts. CRM hygiene is unglamorous. It is also load-bearing. Every downstream workflow depends on the data being accurate, and most teams skip this layer because the output is invisible: a clean CRM looks the same as a messy one until you run a forecast.
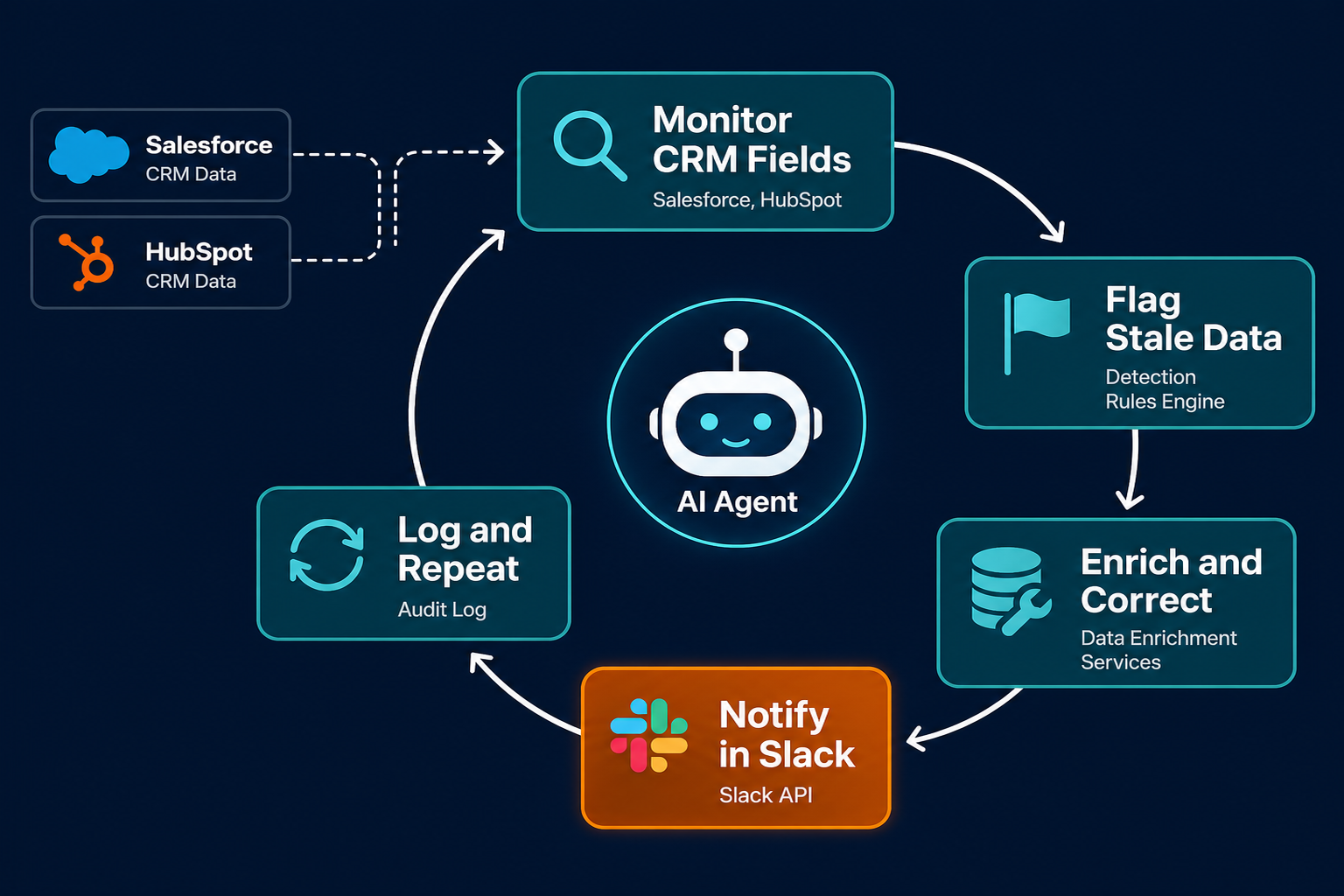
What agents own at the foundation layer:
Contact field validation. Required fields enforced at deal creation and deal update. If a field is empty when it shouldn't be, the agent flags the owning rep in Slack before the deal advances to the next stage.
Deal stage hygiene. Stage-to-stage transition criteria checked at each advance. A deal cannot move from qualification to discovery if the required fields for that transition aren't complete. The agent checks and flags; the rep or manager corrects.
Duplicate detection and merge. New contacts and companies checked against existing records on creation. The agent flags probable duplicates and queues them for merge, reducing the attribution errors that flow into pipeline and territory reports downstream.
Contact enrichment. Gaps in company size, industry, and contact role fields filled automatically from connected data sources. The agent enriches records on creation and runs a weekly enrichment pass for records that have aged without updates.
Stale deal flagging. Open deals with no activity in a defined window (typically 14 days) flagged in a Slack digest each Monday. The RevOps manager reviews the list and either archives stale deals or triggers re-engagement.
For a Salesforce-first stack, the agent connects via a connected app with read/write access to Opportunity, Contact, Account, Activity, and Lead objects. Triggers are field-change events via Salesforce Flow and scheduled sweeps via cron. HubSpot stacks use a private app with equivalent scope on Deals, Contacts, Companies, and Activities. Outreach activity completion events sync to CRM via webhook.
As IBM Think notes on agentic AI systems: agents can specialize in specific tasks, and the simplest agents are those performing a single repetitive task reliably. The foundation layer agent is exactly that: narrowly scoped, running on a schedule, checking one set of criteria and flagging exceptions.
Until CRM data is reliable, every downstream agent is amplifying garbage. The pipeline review agent is useless if the deals it's reviewing have wrong stage dates. The forecast agent is useless if it's working from a pipeline that hasn't been touched in two weeks.
The Middle Layer — Pipeline Review and Forecast Automation
Once the foundation layer has been running cleanly for a full sprint, the middle layer can deliver real value. This is where AI agents have the highest leverage in RevOps: synthesizing signals from Gong, Clari, and Salesforce into pipeline intelligence that a human would have spent hours assembling.
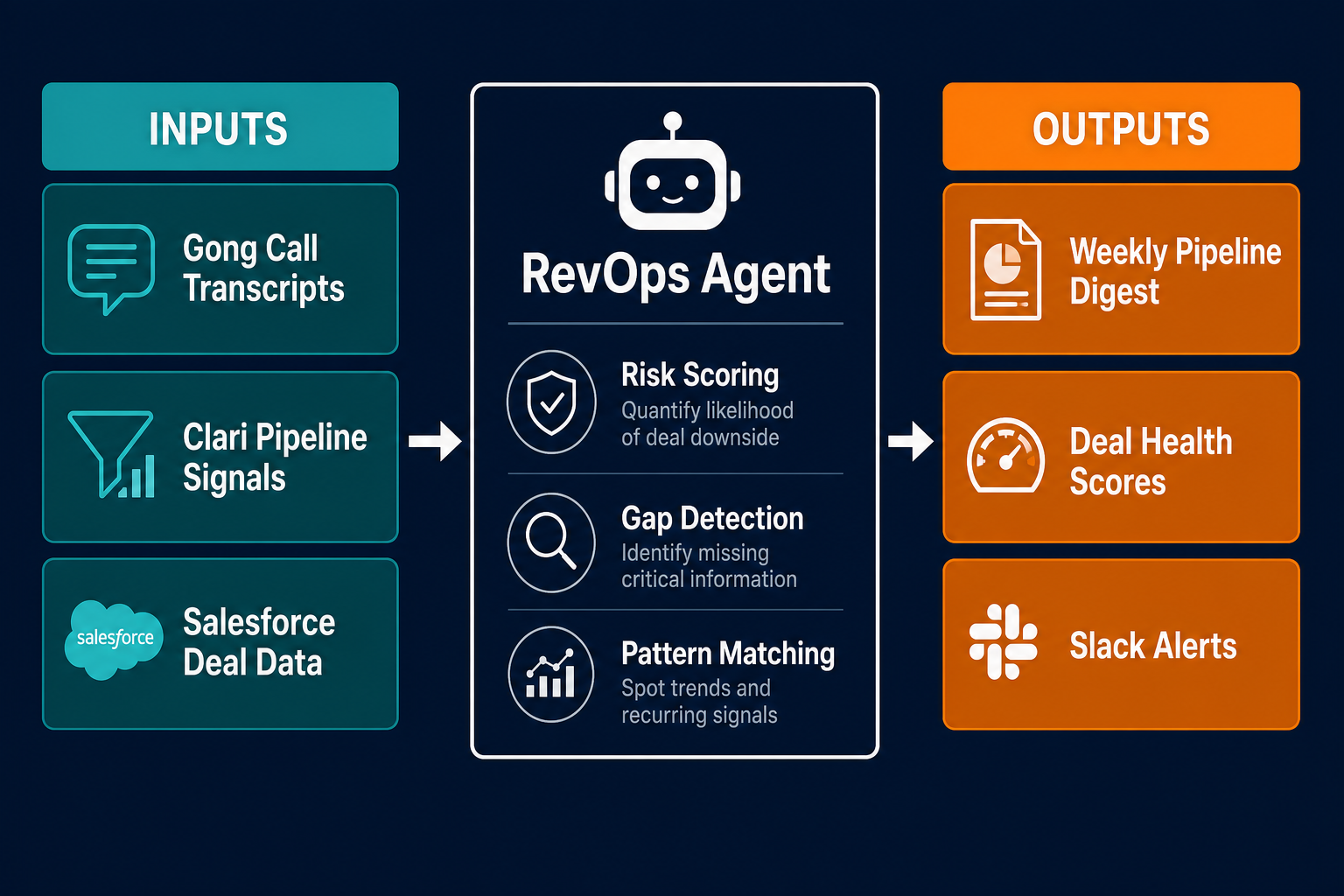
What agents own in the middle layer:
Weekly pipeline review preparation. The agent pulls all open opportunities, scores each for risk based on activity patterns and stage velocity, flags deals that haven't moved in longer than the average cycle time for that stage, and generates the pipeline review document before the Monday meeting. The RevOps manager reviews and approves the digest before it goes to sales leadership.
Call-data-to-CRM sync. The agent reads Gong call transcripts and updates CRM fields with next steps, decision-maker mentions, and objections raised. This keeps the CRM current without requiring reps to update it manually after every call, which is the behavior that keeps foundation layer data reliable over time.
Forecast deviation alerts. The agent compares current pipeline coverage to forecast targets on a rolling basis and flags shortfalls in Slack. If the current quarter's pipeline coverage drops below 3x the forecast target, the RevOps manager gets an alert with the specific deals contributing to the gap.
Deal health scoring. Based on activity patterns, stage velocity, stakeholder engagement signals from Gong, and pipeline coverage data from Clari, the agent assigns a health score to each open deal and updates it weekly. The distribution of scores across the pipeline (percent green, amber, red) gives the RevOps manager an early warning layer that the forecast itself doesn't provide.
A forecast agent trained on manually maintained data isn't an agent. It's an alias for the person doing the maintenance.
None of this is reliable without the foundation layer running clean. A deal health score calculated on stale stage data is not a health score. It is a number that matches what is in the CRM, which is different from a number that tells you what is actually true about the deal.
The Output Layer — Quota Tracking, Territory Visibility, and Deal Desk
The output layer is where RevOps work shows up in board decks and quota conversations. In practice, it is also the layer teams tend to automate first, and the one that fails most visibly when the layers below it aren't clean.

What agents own at the output layer:
Quota attainment visibility. The agent pulls quota attainment data from Salesforce monthly and quarterly, summarizes by rep, team, and geography, and delivers a structured digest to the RevOps manager and sales leadership in Slack. The digest includes attainment percent, gap to target, and the top deals needed to close the gap.
Territory performance reports. The agent identifies territory imbalances weekly: which territories are underperforming relative to quota, which reps have geographic over-concentration, and which segments have pipeline gaps relative to territory assignments.
Deal desk routing. The agent monitors new deals for threshold triggers and automatically routes them to the deal desk (the approval queue for high-value or non-standard deals) when a deal exceeds a size threshold, discount level, or non-standard contract term. This is the one output-layer automation that can run in parallel with the foundation layer, because the trigger fields are typically entered reliably at deal creation even when the rest of the CRM is messy.
Revenue reporting assembly. Quarterly board package data pulled and assembled by the agent. The RevOps manager reviews the output before it goes out, spending 30 minutes reviewing rather than four hours assembling.
The critical constraint: quota attainment digests are only useful if the pipeline data feeding them is accurate. Territory gap reports are only actionable if deal attribution is clean. Automating outputs on top of unreliable data produces confident wrong reports, which are worse than no reports because they carry the appearance of authority.
Wiring the Agent to Your RevOps Stack
Two wiring patterns cover most RevOps agent deployments.
Event-driven wiring fires when a specific event occurs in a connected system: a deal stage changes, a new Gong transcript is available, a deal exceeds a discount threshold. Lower latency, higher precision. Best for time-sensitive workflows like deal desk routing and forecast deviation alerts.
Scheduled wiring runs on a cadence: the nightly CRM hygiene sweep, the Monday morning pipeline digest, the end-of-quarter quota report. Predictable, easier to monitor and debug. Best for the foundation layer and recurring reporting outputs.
Start with scheduled workflows. Add event-driven triggers after the scheduled workflows are stable and the team has developed confidence in the agent's output quality.
Integration checklist for a Salesforce-primary stack:
Salesforce connected app with read/write permissions on Opportunity, Contact, Account, Activity, and Lead objects. HubSpot private app with equivalent read/write on Deals, Contacts, Companies, and Activities. Gong API token with read-only access to calls and transcripts. Clari API access for pipeline and forecast data. Outreach webhook for activity completion events. Slack bot with channels:write and chat:write for digest delivery and alerts.
Human-in-the-loop checkpoint placement:
At the foundation layer, the agent flags and the human corrects. The agent does not self-correct deal stage or record owner fields, because those changes have downstream implications that require judgment.
At the middle layer, the agent surfaces and the human reviews before sharing. The pipeline digest goes to the RevOps manager before it goes to sales leadership.
At the output layer, the agent assembles and the human approves before sending. The quota report goes out with the RevOps manager's sign-off, not directly from the agent.
Anthropic's Building Effective Agents research makes the underlying principle explicit: the most successful agent implementations use simple, composable patterns rather than complex multi-agent orchestration. The RevOps agent stack does not need to be a multi-system orchestration framework on day one. One scheduled hygiene agent and one pipeline digest agent is enough for the first 90 days. For practical guidance on scoping and onboarding any agent built for revenue workflows, the AI agent best practices framework covers the onboarding and correction loop that determines whether an agent stabilizes or stays unpredictable. For agents that touch high-stakes revenue data with human approval checkpoints, human-in-the-loop AI automation covers where to place those approval gates without killing throughput.
Pazi connects to Salesforce, HubSpot, Gong, Clari, Outreach, and Slack through the integrations described above, making it practical to deploy the foundation and middle layer agents described in this guide without building custom infrastructure for each connection.
The most effective RevOps agents start narrow: one system, one workflow, one clearly defined output. Scope creep is the most common failure mode.
The Metrics That Tell You the Sequence Is Working
Metrics confirm that the automation is doing what it's supposed to do and signal when to expand scope. Three measurement layers map to the three automation layers.

Foundation layer metrics (leading indicators):
CRM data completeness: percentage of required fields populated across all open opportunities. Target: above 95 percent. This is the primary signal that the hygiene agent is running and the data is reliable enough to build on.
Stale deal count: number of open opportunities with no activity in the past 14 days. Target: declining week over week in the first four weeks after agent launch. If the count is flat, the agent is either not reaching the right deals or the flagging threshold is too loose.
Duplicate rate: number of duplicate contacts and companies detected per week. Target: declining to near-zero within four weeks. Once the agent is running a nightly sweep, new duplicates should be rare.
Middle layer metrics (lagging indicators):
Forecast accuracy: variance between the pipeline-based forecast and actual quarterly close. Target: below 10 percent variance within 12 weeks of the middle layer running on clean foundation data. This is the lagging indicator that the whole sequence is working.
Pipeline review prep time: hours spent by the RevOps manager preparing the weekly pipeline review. Target: from roughly four hours to under 30 minutes within the first month.
Deal health score distribution: percentage of open deals scoring green, amber, and red. A spike in red-scoring deals two months before quarter close gives you time to act. The forecast won't show it yet.
Output layer metrics:
Ops hours per sprint: total RevOps team hours spent on report assembly, quota tracking, and deal desk routing. Target: above 50 percent reduction within two quarters of output layer automation running on stable middle layer data.
Deal desk cycle time: hours from deal desk submission to approval. Target: reduction proportional to routing automation coverage. If 70 percent of deals route automatically, cycle time should drop by at least 50 percent.
Quota attainment report frequency: from a monthly manual pull to a weekly automated digest. If it's still monthly after the output layer is running, the agent isn't completing.
| Layer | Leading indicator | Lagging indicator | Expansion trigger |
|---|---|---|---|
| Foundation (CRM hygiene) | CRM completeness % | Duplicate rate declining | 4 consecutive green weeks |
| Middle (pipeline and forecast) | Deal health score distribution | Forecast accuracy vs. actuals | Below 15% variance for 2 quarters |
| Output (quota and deal desk) | Report frequency (weekly vs. monthly) | Ops hours per sprint | Middle layer stable |
The expansion sequence is as important as the metric targets. When foundation layer metrics have been green for four or more consecutive weeks, the middle layer can safely expand. When middle layer forecast accuracy variance is below 15 percent, the output layer scope can increase.
For a RevOps manager at a 50-person B2B SaaS team on Salesforce and Gong, the weekly measurement ritual is a 15-minute Slack digest review: three numbers, CRM completeness, top five at-risk deals, and forecast coverage versus target. If all three are within threshold, the week starts clean. If any are off, the agent has already flagged the specific deals or fields causing the issue. That is the goal state. More than 15 minutes means the sequence is not complete.
For teams that have already automated engineering incident workflows, the incident response automation framework uses the same per-layer measurement logic: confirm the foundation is stable before expanding scope.
Related Reading
- How to Automate Account Management with AI Agents
- AI Agent Best Practices: 7 Rules from Running Them at Pazi
- Human-in-the-Loop AI Automation: Designing Oversight Without Killing Throughput
- How to Automate Incident Response with AI Agents
Pazi is a platform for building and running AI agents across the tools your RevOps team already works in: Salesforce, HubSpot, Gong, Clari, Slack. You define the sequence, the thresholds, and the escalation logic; the agent runs the coordination layer while your team focuses on the forecast conversations that require human judgment. If your pipeline data is ready, the agent is.



