
Human-in-the-loop AI automation is the practice of embedding human decision points into an AI pipeline at positions where machine judgment alone carries unacceptable risk. Most operators get the calibration wrong in one of two directions: they gate every step and call it governance, or they gate nothing and call it efficiency, and both failures look fine until the pipeline breaks at the worst possible moment.
This guide explains how to design oversight that holds. It covers the three-factor framework for deciding where to add checkpoints, four implementation patterns matched to different risk profiles, team-specific examples for DevOps and Product teams, and five KPIs to keep calibration honest as the system matures.
Table of Contents
- The Calibration Problem: Why HITL Fails in Both Directions
- Where Autonomous Pipelines Break Without Oversight
- The Checkpoint Decision Framework
- Implementation Patterns for Production Pipelines
- Team-Type Use Cases
- Measuring Whether Your HITL Is Calibrated
The Calibration Problem: Why HITL Fails in Both Directions
Most teams approach human-in-the-loop as a posture question: do we trust AI to do this or not? That framing produces bad outcomes in both directions.
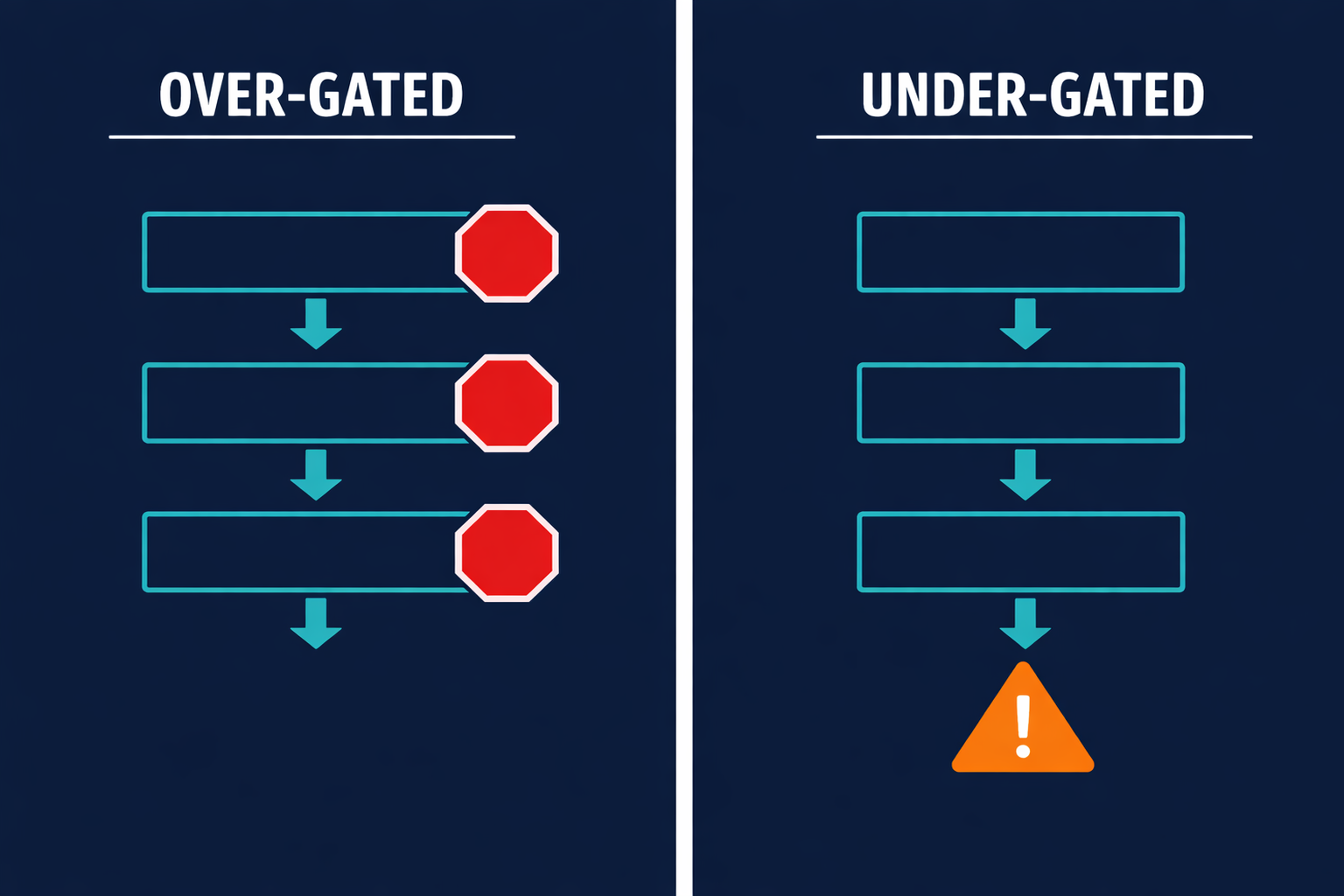
The first failure is over-gating. When every significant step requires human approval, the agent does not save time. It just relocates the bottleneck. The human is now the rate limiter, and the AI adds latency without adding leverage. Teams that over-gate often report that their automation feels slower than doing the work manually, which is true, because it is. The AI is producing work product and immediately parking it in a human's queue.
The second failure is under-gating. Removing oversight entirely means failures accumulate silently. The agent handles the routine cases well, which creates confidence. Then it encounters an edge case, handles it wrong with high confidence, and the error propagates without triggering any alert. By the time a human sees it, the mistake is expensive to undo.
Both failures share a root cause: operators treat HITL as a binary setting rather than a calibration dial. The right question is not whether to trust AI, but at which specific decision points does human input change the outcome enough to justify the throughput cost?
| Symptom | What it signals |
|---|---|
| Humans approve every agent output without changes | Over-gated: the gate adds friction but no value |
| Pipeline cycle time increased after adding AI | Over-gated: bottleneck shifted from work to approval |
| Errors appear only after external stakeholders notice | Under-gated: failures accumulate without escalation |
| Agent handles 95% of cases; the other 5% are expensive to fix | Under-gated: edge cases need a gate, not a restart |
| Team is confident in the agent but can't explain why | Under-gated: no instrumentation, no correction history |
| Approval rate is consistently above 95% | Over-gated: gate is catching nothing meaningful |
The calibration goal is neither minimum oversight nor maximum oversight. It is optimal oversight: the right gate at the right point for the right task class, adjusted over time as correction history accumulates.
Where Autonomous Pipelines Break Without Oversight
Operators who run fully autonomous agents in production encounter three failure categories repeatedly.

Edge cases outside the training distribution. The agent handles familiar inputs well. On inputs it has not seen at sufficient frequency, it produces plausible-looking but wrong outputs, and it produces them with high confidence. The problem is not that the model is uncertain. It is that model confidence does not reliably correlate with model correctness. Operators who use the model's own certainty score as an oversight trigger will find it fires on the wrong things.
High-stakes irreversible actions. Some things cannot be undone quickly: a customer email sent, a production deployment triggered, a database record deleted, a webhook fired to an external system. These actions have asymmetric cost profiles. The cost of a missed approval is small. The cost of an unchecked error can be very large. This asymmetry is the primary reason to add a hard gate, independent of how well the agent performs on average.
Ambiguous-intent inputs. When an instruction has two equally valid interpretations, the right response is to surface the ambiguity to a human. An autonomous agent picks one interpretation and proceeds. If it picks wrong, the human now has to undo a completed action rather than answer a quick clarifying question. The math on this is straightforward: clarification before action is almost always cheaper than correction after action.
"The goal of HITL is to allow AI systems to achieve the efficiency of automation without sacrificing the precision, nuance and ethical reasoning of human oversight."
IBM Think
The regulatory dimension is arriving as well. EU AI Act Article 14 mandates that high-risk AI systems be designed so that "natural persons can effectively oversee" them during use. For operators in regulated industries (finance, healthcare, hiring), this requirement is moving from best practice to legal obligation. Designing for oversight now is less expensive than retrofitting for it later.
The Checkpoint Decision Framework
Before choosing a checkpoint type (or no checkpoint), run every task class through a three-factor test. This test produces a consistent, auditable record of why each gate is or is not in place.
Factor 1: Consequence magnitude. If this action is wrong, what is the blast radius? Score it: low (output error, easily caught and corrected), medium (internal rework, costs hours), or high (external action with real-world effect: a customer message, a financial transaction, a production change). High-consequence actions are the primary candidates for hard oversight.
Factor 2: Reversibility. Can the action be undone in under five minutes? Under an hour? At all? An email sent is irreversible. A draft saved is reversible. A database row deleted without a backup is irreversible. A feature flag change to 0.1% of users is practically reversible; the same change to 50% of users is not. Irreversibility compounds consequence: a low-consequence irreversible action may still warrant a gate because the correction cost is unbounded.
Factor 3: Confidence track record. Over the last N runs of this task class, what percentage required human correction? This number must come from your correction history, not from the model's self-reported certainty score. The two are different things. A model can report high confidence on tasks it consistently gets wrong. Your correction history does not lie. As a rough threshold: below 5% correction rate, the task class is a candidate for automation with logging only. Above 20%, add a checkpoint.
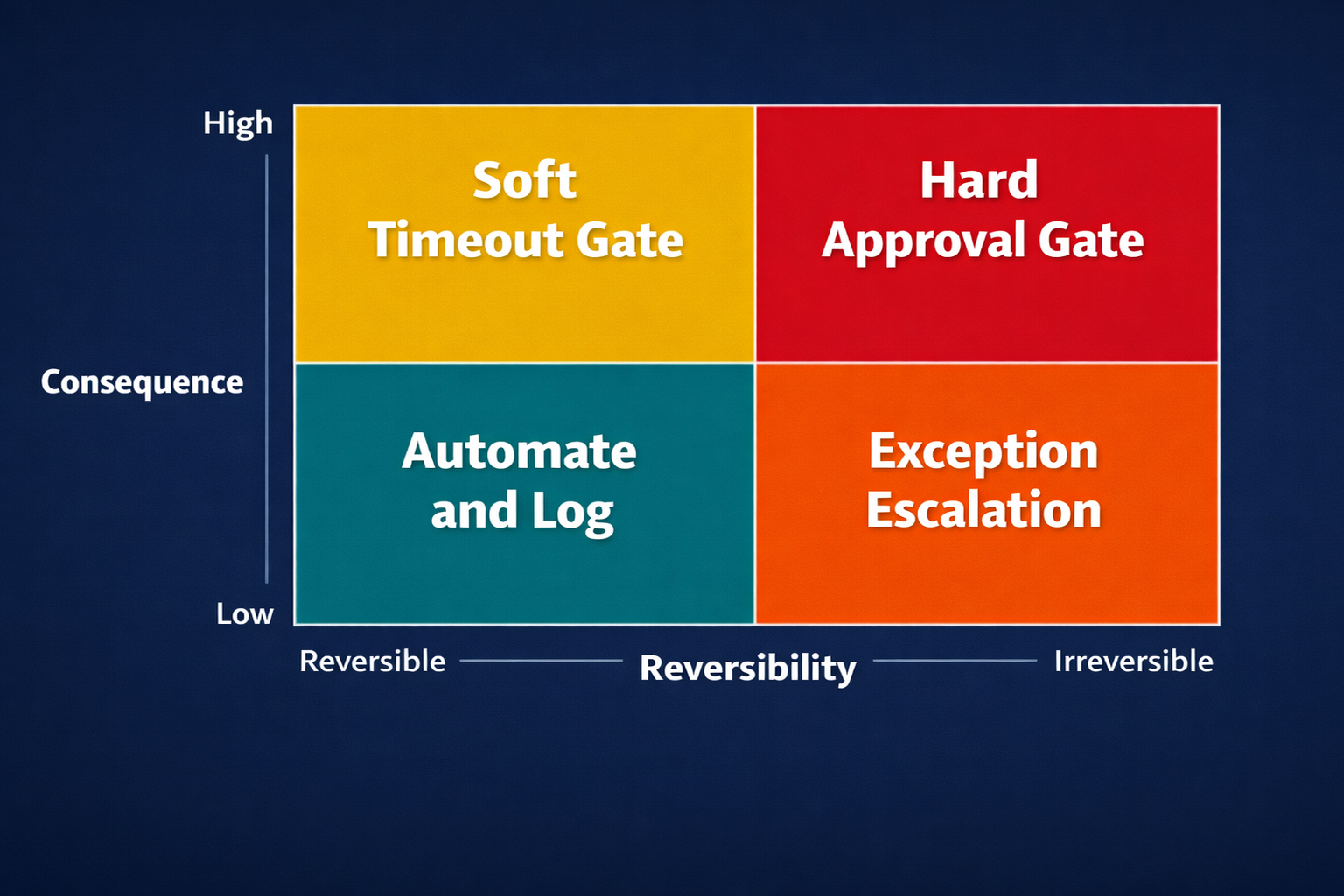
The matrix these three factors produce has four zones:
| Consequence | Reversibility | Recommended gate |
|---|---|---|
| Low | Reversible | Automate with logging only |
| High | Reversible | Soft timeout gate |
| Low | Irreversible | Exception escalation |
| High | Irreversible | Hard approval gate |
One zone gets missed most often: the "automate with logging only" quadrant. Low consequence, reversible, correction rate below 5%, this is the space where HITL adds friction without adding value. Many operators gate this unnecessarily because they have not yet built a correction history. The practical fix: run the task class with a human watching for two to four weeks before adding any gate. Build the track record first, then decide.
The OpenAI framework on governing agentic AI systems frames this well: operators, developers, and deployers each carry baseline responsibilities for safe system behavior. The checkpoint framework is how operators discharge their share of that responsibility at the pipeline level.
Implementation Patterns for Production Pipelines
Once the decision matrix identifies which quadrant a task class falls into, the implementation pattern follows directly. There are four checkpoint types in production use.
Hard approval gate. The agent pauses its run completely, holds state, sends a notification to a human, and waits for an explicit approval response before proceeding. There is no auto-proceed timeout. The agent waits indefinitely. Used for: irreversible, high-consequence actions where an unchecked error cannot be walked back (production deployments, external financial actions, customer-facing decisions with legal or relationship risk). In OpenClaw, implement these as HARD WAIT states: the agent sets a flag in the working thread, stops all downstream processing, and resumes only when an explicit approval message arrives.
Soft timeout gate. The agent pauses, sends a notification, and auto-proceeds if no human response arrives within a defined window. Every auto-proceed event is logged for post-hoc review. Used for: time-sensitive flows where a blocked gate is more damaging than an occasional unchecked action. The key discipline here is the log: without it, the auto-proceed pattern is just undocumented autonomy, and you lose the correction history you need for calibration.
Exception escalation (tripwire model). The agent runs autonomously. It escalates only when a structured validation function fires: an output schema mismatch, a business rule violation, or an anomaly detector threshold crossed. Used for: high-volume task classes with a low correction rate, where pre-emptive gating on every run would create unnecessary overhead. The tripwire pattern is underused. Most teams default to pre-emptive gating when exception escalation would cover the same risk at a fraction of the throughput cost.
Confidence threshold trigger. The agent compares its output against a structured validator (schema check, sentiment classifier, business rule) and routes to human review when the validation score falls below a threshold. Used for: structured output pipelines where correctness is verifiable programmatically. Unlike self-reported model confidence, the validator is an independent function whose calibration can be tested and adjusted.
"When building applications with LLMs, we recommend finding the simplest solution possible, and only increasing complexity when needed. Agentic systems often trade latency and cost for better task performance, and you should consider when this tradeoff makes sense."
Anthropic, Building Effective Agents
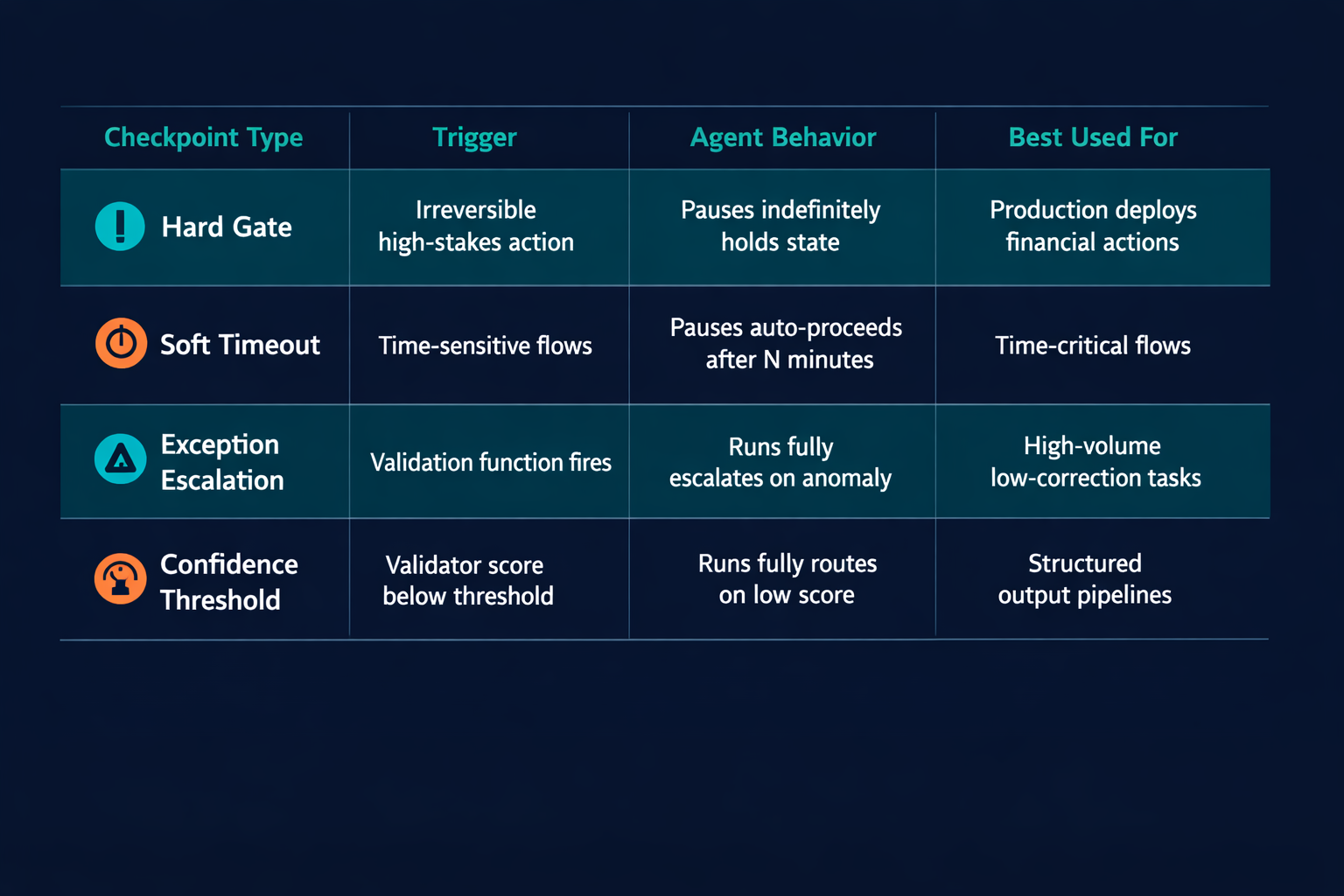
| Checkpoint type | When gate triggers | Agent behavior | Human role |
|---|---|---|---|
| Hard gate | Before every run of this action | Pauses indefinitely, holds state | Required: explicit approve or reject |
| Soft timeout | Before run, on timer | Pauses, auto-proceeds after N minutes | Optional: intervene within window |
| Exception escalation | After run, on validation failure | Runs fully, escalates on anomaly | Reactive: reviews flagged outputs only |
| Confidence threshold | After run, on validator score | Runs fully, escalates on low score | Reactive: reviews outputs below threshold |
In OpenClaw, exception escalation is implemented via HEARTBEAT.md compliance checks: the agent logs each task output, the heartbeat validates completion criteria, and escalates if output is stale, anomalous, or outside expected bounds. This keeps the happy path fully automated and surfaces only genuine failures.
Team-Type Use Cases
The checkpoint framework applies across team types. Two concrete examples from the teams running agents most aggressively in production.
DevOps and SRE
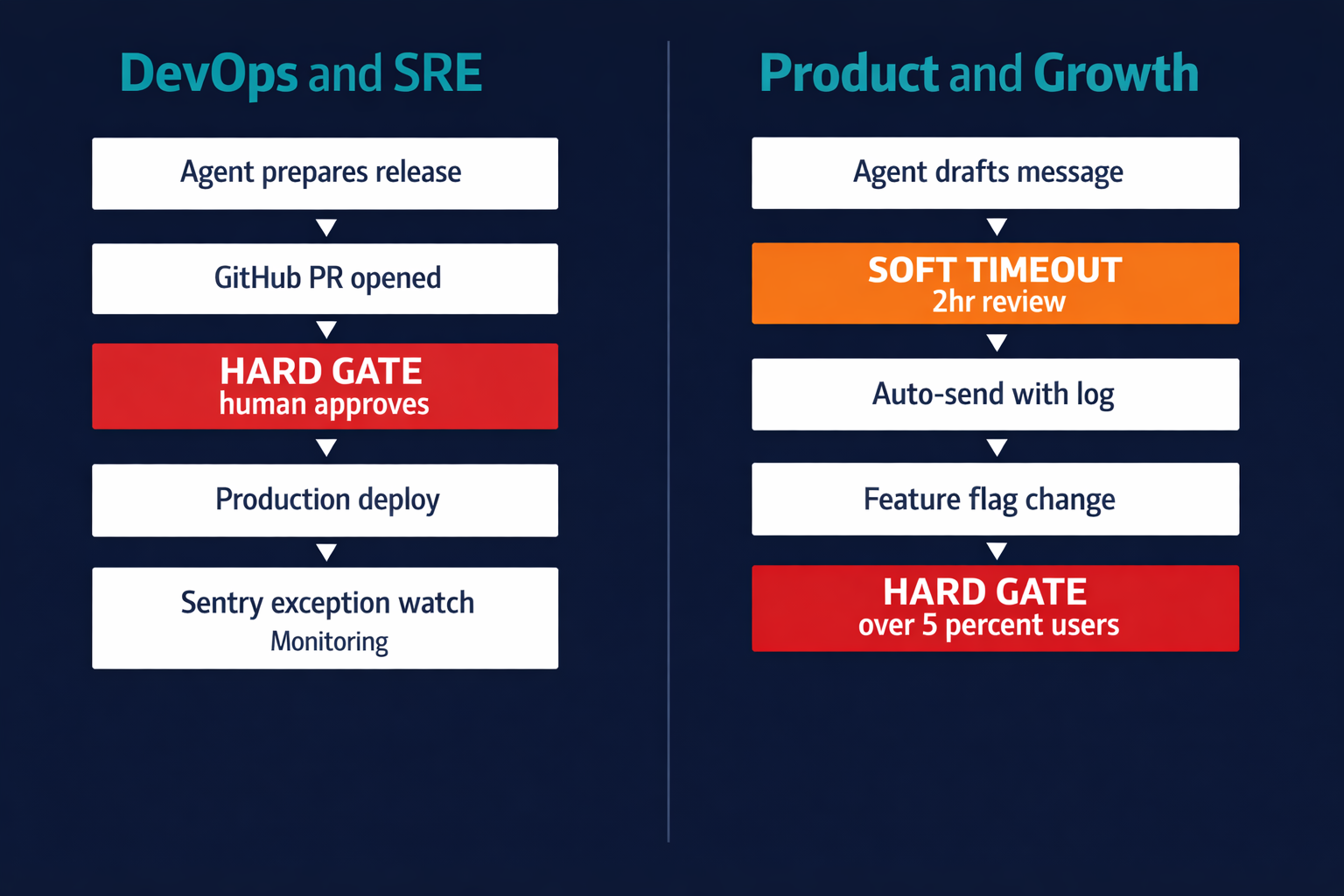
A deployment pipeline is a common first candidate for automation. The agent handles the preparation work: changelog generation, version bump, release notes, opening the GitHub PR. None of that requires a gate. The gate belongs at the production push: the agent sends a Slack notification with the PR link and waits for explicit approval before triggering the merge and deploy. Consequence is high (production system). Reversibility is low (a bad deploy costs rollback time and incident hours). Hard gate.
Incident response uses a different pattern. A Sentry alert fires. The agent pulls the stack trace, drafts the incident summary and initial response steps, and creates a Linear card. The agent notifies the on-call engineer with the draft. If the engineer takes no action within 15 minutes, the agent auto-proceeds with the first-response step (status page update, stakeholder ping). This is a soft timeout gate: the response is time-sensitive, but the first-response step is reversible and low-blast-radius. Hard gate on any agent action that modifies production infrastructure directly.
Tool stack: GitHub, Linear, Sentry, Slack. The agent touches all four. The gate placement is per-action, not per-tool.
Product and Growth
A user-facing communication agent drafts onboarding nudges, churn-risk outreach, and in-app messages. The agent queues each message and notifies the team. If no one flags it within two hours, it auto-sends with a log entry. Soft timeout gate. The exception to soft timeout: any message to a customer with an open support ticket routes to a hard gate. Sending automated outreach to a frustrated customer is high-consequence and partially irreversible (the customer sees it regardless of what happens next).
Feature flag management uses a simpler split. The agent executes flag changes for internal beta audiences (less than 1% of users) without any gate. Hard gate before any change affecting more than 5% of production users: the agent sends the proposed flag change to Slack with a PostHog summary of the affected cohort, and waits for explicit approval.
Tool stack: Linear, Intercom, PostHog, Slack.
The calibration discipline is identical across both teams. The task class changes. The three-factor test and the gate types do not.
Measuring Whether Your HITL Is Calibrated
HITL cannot be calibrated without measurement. Teams that add gates and never instrument them accumulate invisible overhead with no feedback loop. Five KPIs cover the full signal set.

Approval rate: the percentage of escalations approved without modification. Target range: 50 to 80 percent. Consistently above 90 percent means the gate is catching nothing meaningful; the human is rubber-stamping, not governing. That gate is a candidate for downgrade to exception escalation or removal. Consistently below 40 percent means the model's output on this task class is not production-ready; adding more gates does not fix that.
Time-to-approval: average time from escalation notification to human response. Target: within 30 minutes for time-sensitive flows. A rising trend signals either notification failure (the human is not seeing the gate) or gate fatigue (the gate fires so often the human is deprioritizing it). Both are calibration failures.
False escalation rate: escalations where the human approves with zero edits. These are the clearest signal that the gate threshold is miscalibrated. The human is being pulled in to confirm something the agent had right. Over time, consistently zero-edit approvals identify which gates should be converted to tripwires.
Override frequency: escalations where the human materially changes the agent's proposed output before approving. Sustained override rate above 25 percent means the model's output on this task class is drifting or systematically wrong on a specific input type. The right response is to feed corrections back as training signal or structured examples, not to add more gates.
Throughput delta: pipeline completion rate and average cycle time with HITL gates active versus a logging-only baseline for the same task class. This makes the cost of each checkpoint visible in concrete terms. It is the required context for any gate-removal decision: you need to know what throughput you gain when you remove a gate, and compare that against the correction rate you saw when you ran without one.
Run this analysis monthly. A gate calibrated correctly at launch may be wrong 90 days later. Correction rates drop as the task class matures and the model accumulates more representative examples. Gates that started as hard gates often graduate to soft timeouts, then to exception escalation, then to logging only. That progression is healthy and expected. The goal is to keep the gates moving in the right direction, not to maintain them forever.
Designing Oversight That Holds
Human-in-the-loop automation is a calibration problem, not a trust problem. The teams running AI agents successfully in production are not asking whether to trust AI. They are specifying, for each task class, at which decision point human judgment changes the outcome enough to justify the throughput cost.
Start with the three-factor test on your highest-consequence task class. Score consequence magnitude, reversibility, and your correction track record. Place the checkpoint the matrix points to. Instrument all five KPIs from day one. Revisit monthly.
If you are building on OpenClaw, the hard gate and exception escalation patterns ship with the platform. Hard gates are HARD WAIT states in the working thread. Exception escalation runs through HEARTBEAT.md compliance checks. Start there, run with a human watching, and calibrate toward the lightest-touch gate that your correction history supports.
For more on building AI agent pipelines that hold up in production, see how to onboard AI agents, how AI agents close the engineering gap, and how to add self-monitoring to your OpenClaw agent.
See how Pazi runs calibrated human-in-the-loop automation in production.



