
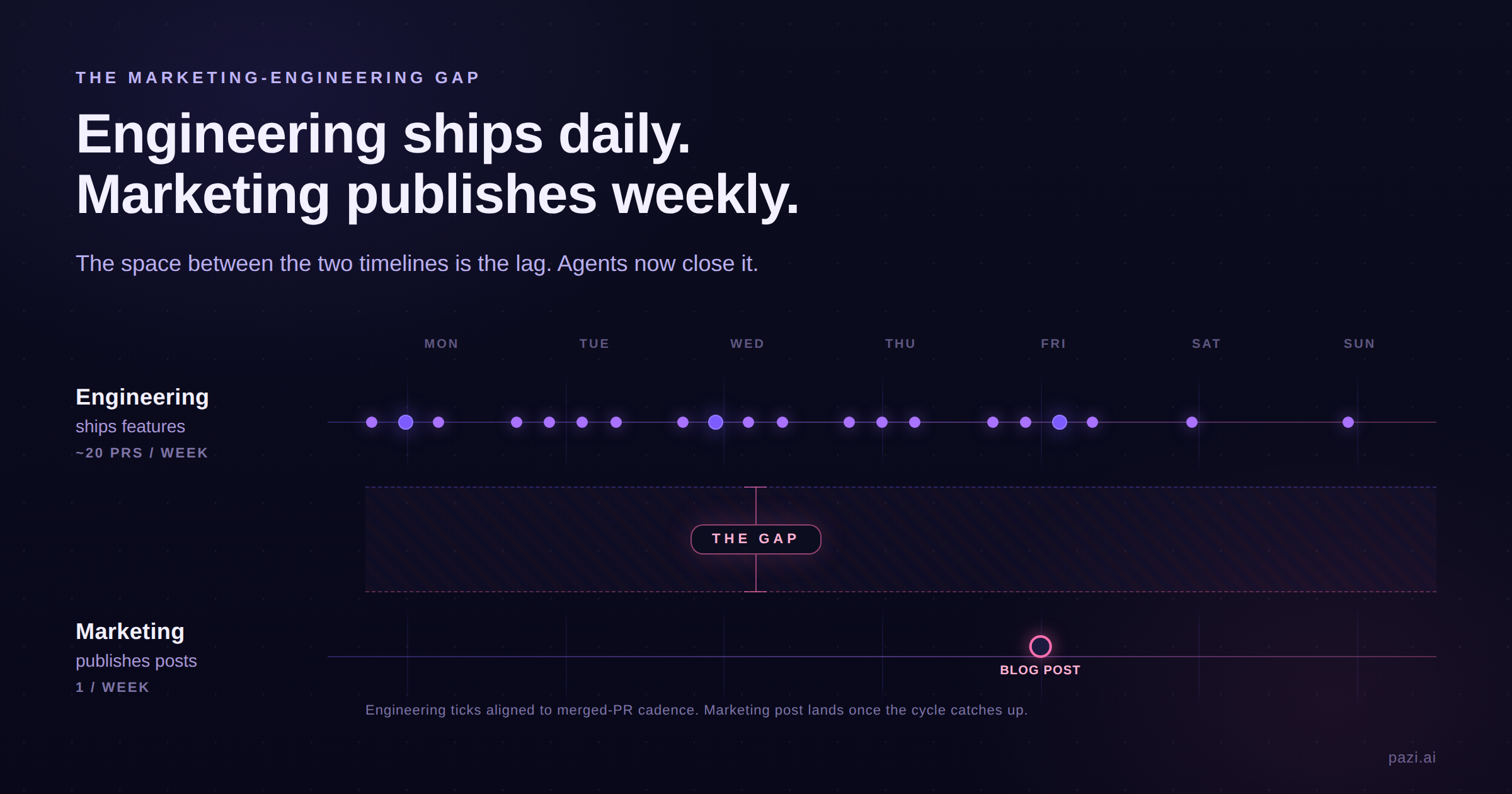
The marketing-engineering gap is the time between when engineering ships a feature and when marketing publishes anything about it. At most B2B SaaS companies the gap runs days to weeks, while engineering ships multiple times a day. The cost is mostly invisible because it accrues in categories that don't appear on a dashboard: launch windows that close before the post lands, indexing races that get won by whoever publishes first, and sales enablement that runs a week behind the feature it needs to sell.
Operators, devrel leads, and PMM at series-A and B companies feel this gap most acutely because they watch engineering velocity outrun their content velocity every week. Other functions are already adopting the same structural fix in adjacent lanes by putting an agent on the upstream surface with a human in the editorial role above it.
Why the gap exists
Engineering teams ship faster than marketing teams write, and they always have. DORA's research on software-delivery cadence has documented this for over a decade, with elite-performing teams deploying multiple times per day and lower performers shipping monthly. The marketing-content side of those same companies has never had a comparable cadence metric, because the work has always been throughput-bound on a human writer reading the changes and deciding what is worth writing about.
The asymmetry is baked into the org chart: a four-person content team at a series-B SaaS company runs PMM, content marketer, devrel, and competitive intel as four separate seats, each one consuming the same upstream signals through a different filter on a weekly or quarterly cadence. Engineering ships in hours and the content team responds in weeks because the bottleneck is a single human reading the signals before anyone can write about them.
The cost of the lag is invisible because the lost outcomes never appear on a dashboard. Each delay carries a category of cost: the launch window for the feature closes on a fixed clock, the indexing race is won by whoever publishes first (often a competitor with a comparison post that frames the feature on their terms), and internal sales waits on marketing for the one-pager it needed at launch. None of those costs show up in any tracking tool, which is why the gap persists at companies that otherwise have their content function running well.
What's actually changing in 2026
The substrate that makes engineering-monitoring agents possible has been getting built piece by piece by the platform vendors most operators already use.
Linear shipped Code Intelligence in May 2026, framed as "controlled access to your codebase, turning repositories into shared product context your whole team can use." The agent reads the code itself, which is the floor for everything downstream including drafting a blog post from a merged PR diff.
Vercel pushed natural-language firewall rules in the same window, while Mintlify positions its docs platform on "AI into every part of your docs lifecycle." The three vendors are building the same substrate from three different starting points, with the application layer for marketing teams running one level above.
GitHub supplies the lowest-floor primitive: auto-generated release notes from PR titles, available for years. Most teams turn it on, see the JIRA-changelog output, and stop looking. An agent on top of that primitive turns the bullet list into a blog post by reading the diff, deciding whether the change is post-worthy, drafting in your blog's voice, and routing the result to a human for one approval before publish. The substrate is in place; the application layer is the next thing to build.
A separate category is emerging that runs the same agent pattern in adjacent lanes. Common Room positions its product as "Revenue agents built on complete buyer intelligence" for the sales side, and Crayon customers describe "Sparks that automatically run weekly and monthly to keep everyone up-to-date on the competition." Both have proven the agent shape works in production. The engineering-surface lane is the one with the most direct line to what marketing actually publishes, which is why the leverage compounds fastest there.
| Rule | One-line discipline |
|---|---|
| 1. Triage hard, ship less | ✅ Most repo activity is not post-worthy; the agent filters before it drafts |
| 2. Voice is the moat | ✅ Codify voice in a file the agent reads on every run; treat drift as a config problem |
| 3. One approval gate, every time | ✅ Full autonomy is a credibility leak; one human gate is the floor |
| 4. Docs first, blog post second | ✅ Docs continuity is the structural payoff; the blog post is the visible one |
| 5. Track what shipped vs what got read | ✅ Volume without per-channel feedback is theater |
Rule 1. Triage hard, ship less
The first instinct after wiring an agent to the repo is to write a post about everything, which is the failure mode. Most repo activity is not post-worthy and it never will be: routing fixes, dependency bumps, internal refactors, test additions, environment-variable renames.
The agent has to triage at the ingest stage by scoring every merged PR against three tiers: Gold for a user-facing feature, Silver for polish or reliability or a UX improvement, and Bronze for internal plumbing. In every rubric we have seen run in production most repo activity comes back Bronze, and without that filter the agent drafts about every refactor until the operator stops reading the queue.
Anthropic's multi-agent research describes the same failure shape from a different angle, with their early agents "spawning 50 subagents for simple queries, scouring the web endlessly for nonexistent sources, and distracting each other with excessive updates." Their fix was bounding what each subagent was allowed to do, and the equivalent move for a content agent is bounding what counts as worth writing about, applied at the ingest step before any drafting begins.
Rule 2. Voice is the moat; codify it before the agent learns the wrong one
Without a codified voice file, the agent converges on the cadence of its training data, which is the global mean of B2B SaaS content. The blog post lands competent and unread because brand voice was the small differentiation that made one blog feel different from another, and once it drifts to the mean the differentiation erodes before anyone on the team notices.
The voice file is two or three pages the agent reads on every drafting run. It lists the phrases you do not use, the sentence shapes you do, the cadence rules per surface, and a handful of sample paragraphs in your actual voice. When a draft drifts off the voice, the operator edits the file rather than the draft, because the file produces the next hundred drafts and the draft produces only one.
Anthropic's writeup on shipping agents to production lands on the same operational pattern, namely that "the most successful implementations weren't using complex frameworks or specialized libraries. Instead, they were building with simple, composable patterns." A markdown voice file the agent loads on demand is one of those simple composable patterns running in the wild.
Rule 3. One approval gate, every time
Full autonomy is the most tempting and most expensive failure mode, because the trap shape is well-known across autonomous systems. The agent runs clean for long enough that the human in the loop trusts the floor and drops the review step. When the upstream signal shifts in a way the agent can't see (a rollback, a renamed feature, a security regression hitting between draft and publish), the bad output ships unreviewed. The post lives on the blog after that, and the trust cost from one inaccurate post is more than the recurring two-minute review time ever saved.
Keep one human approval gate every time, even when the agent has earned trust and even when the queue is long. The shape that works is a Slack DM or Discord message with the draft inline and a single /approve token at the bottom. The agent drafts, the human signs off in the same thread, and the post ships within seconds of approval.
The gate is what keeps the pipeline trustworthy enough to scale, because drafts fail when the upstream signal changes shape (a rolled-back PR, a last-minute name change, a security regression hitting the same day) and the agent does not know any of that on its own.
Rule 4. Docs first, blog post second
Marketing teams treat docs as the lower-prestige work and the agent learns to prioritize the visible output, so over time the blog stays current and the docs drift behind. The cost shows up in three categories: new users hitting reference pages that don't match the live product, support tickets growing on questions the docs should have answered, and devrel time consumed by rewrites that should have been side effects of the original ship.
Every feature-shipping run updates the docs first, then drafts the post. The order matters because docs continuity is the structural payoff, while the blog post is the visible one and the easier one to remember to do. Wire the docs update into the same daily run as the blog draft so the docs stay current as a side effect of the post-drafting work.
The multi-agent pattern earns its keep here, because a senior agent on your workspace can stand up a docs-specific agent at runtime (one example of the agent-creates-agent pattern) and hand the docs work to it. The docs agent owns one narrow job, with its own voice file calibrated for reference prose, and runs on the same approval gate the writer agent uses, which keeps both surfaces current without doubling the operator's review load.
Rule 5. Track what shipped vs what got read
Velocity hides the last failure mode: the agent ships content on a daily cron and the volume climbs, but if the per-channel engagement numbers stay flat, the velocity is decoupled from reach. The team is shipping more content; nobody is reading more of it.
The same agent that publishes also tracks. It sends per-channel analytics back to the operator within 24 hours of publish, covering what landed on X, on dev.to, on Hacker News, and on long-tail search.
Those numbers feed the writer agent's next prompt update on a slow cadence the operator can read through on a Sunday evening. The volume stays attached to the work of making the next post better, which is how a content pipeline becomes content marketing rather than content production at a higher cadence.
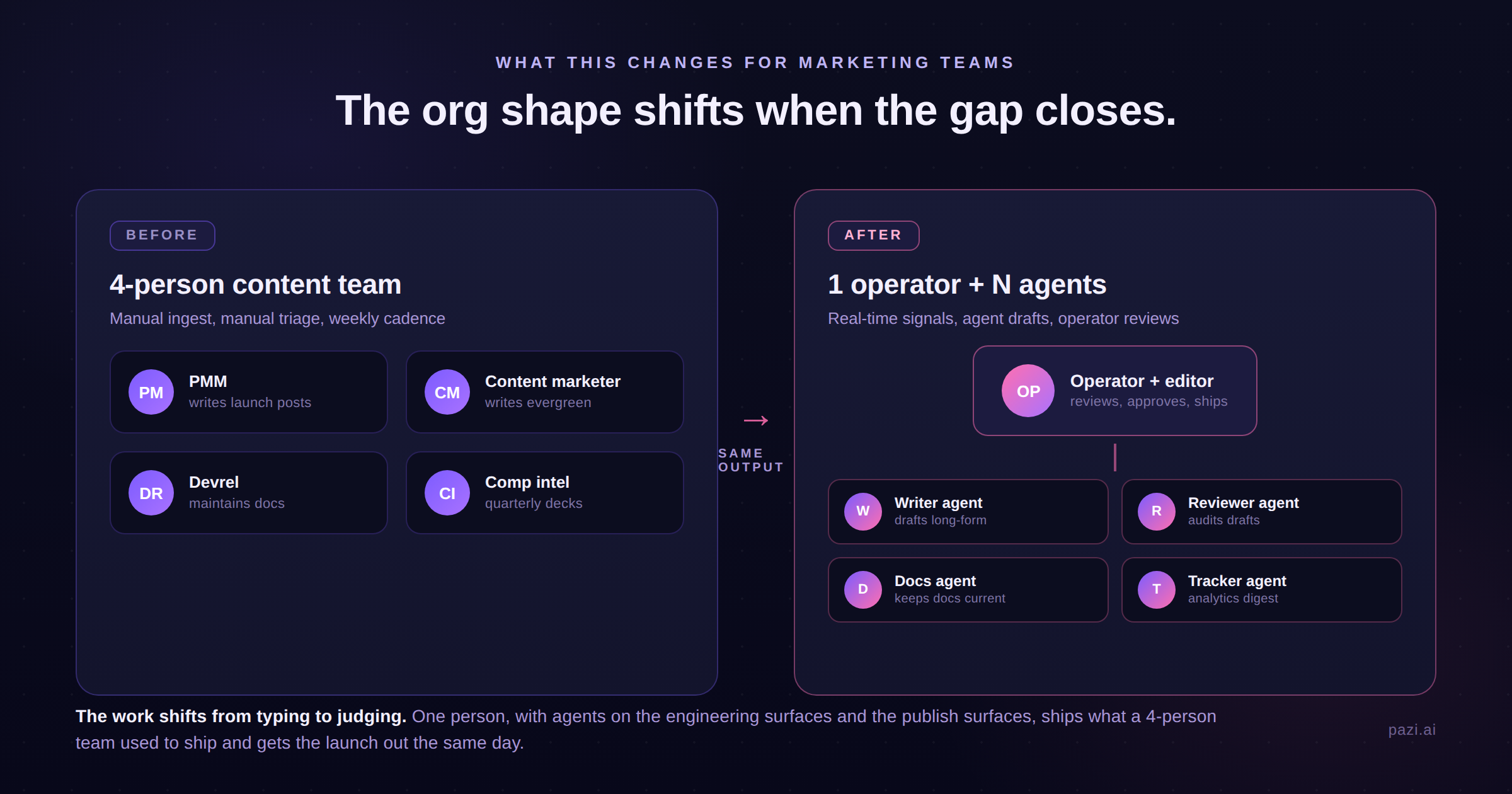
What this changes for marketing teams
Once the agents handle the drafting and the cross-channel posting, the marketing team's headcount math changes. One operator running a small fleet of narrow agents covers what used to require four full-time seats (PMM, content marketer, devrel, competitive intel) by sitting at the approval gate, editing on the misses, and updating the voice file when drafts drift off voice across multiple posts.
The same restructure happens in devrel, where the docs agent picks up the stale-docs rewrites that used to occupy a chunk of every devrel week and leaves the human in the loop on prompt updates, edge cases, and final approval before docs ship to production. The time that was getting consumed by repeated reference-page rewrites moves to community engagement, demos, and conference work, which is the slate of activities that doesn't run on a docs-shipping cadence and was never going to agent-automate cleanly anyway.
Competitive intel sees the same restructure on its own lane, with the quarterly competitive deck becoming weekly synthesis from a continuous monitoring agent and the human in the loop tuning the questions and reviewing the synthesis before it gets routed to revenue.
The marketing-engineering gap closes for every team that puts agents on three surfaces: the engineering signal (PRs, releases, commits), the publish surface (blog, X, dev.to, Discord), and the docs surface. The teams that close it first set the AEO and competitive-positioning ceiling for everyone else, the same way the elite-performing engineering teams in the DORA benchmarks set the ceiling for engineering cadence. The lag was always a throughput constraint on the human reading the signals, and the constraint comes off when an agent reads them first.
See seven rules for onboarding AI agents for the broader framework on running agents in production, or read agents can now create agents for the multi-agent pattern referenced in Rule 4.
This framework came out of running the pattern in production and watching it work in adjacent teams running variants of the same setup. The mechanics differ team to team, but the underlying structure of agent-on-upstream-surface plus human-at-the-gate holds.
Build the team that closes the gap on yours.
The framework runs on Pazi. Stand up your first content agent at pazi.ai.



