For the average software company, 66% of sales opportunities are competitive. Two thirds of every deal a marketing team is trying to win is shaped by what someone else is doing, and the work of staying ahead of that is the work most teams keep meaning to get to.
In practice, competitive intelligence is a job everyone says they do and almost no one does well. Founders run it on Sundays. The marketing teams that subscribe to a CI platform stop opening the alerts after the second month, and the product marketers who build a battlecard once a quarter watch it go stale by week two. The bottleneck isn't seeing what competitors are doing, because RSS, Google Alerts, and page-change tools have mostly solved that part. The bottleneck is the work between the signal and the decision: reading the change, deciding if it matters, deciding what to do about it, getting the right person looped in, and following up next week to make sure we actually did the thing. The tooling that exists has only ever instrumented two stages of that work. The full job is closer to ten, and an agent that runs all ten is a different shape from a tool that runs two.
What an AI agent for competitor research actually is
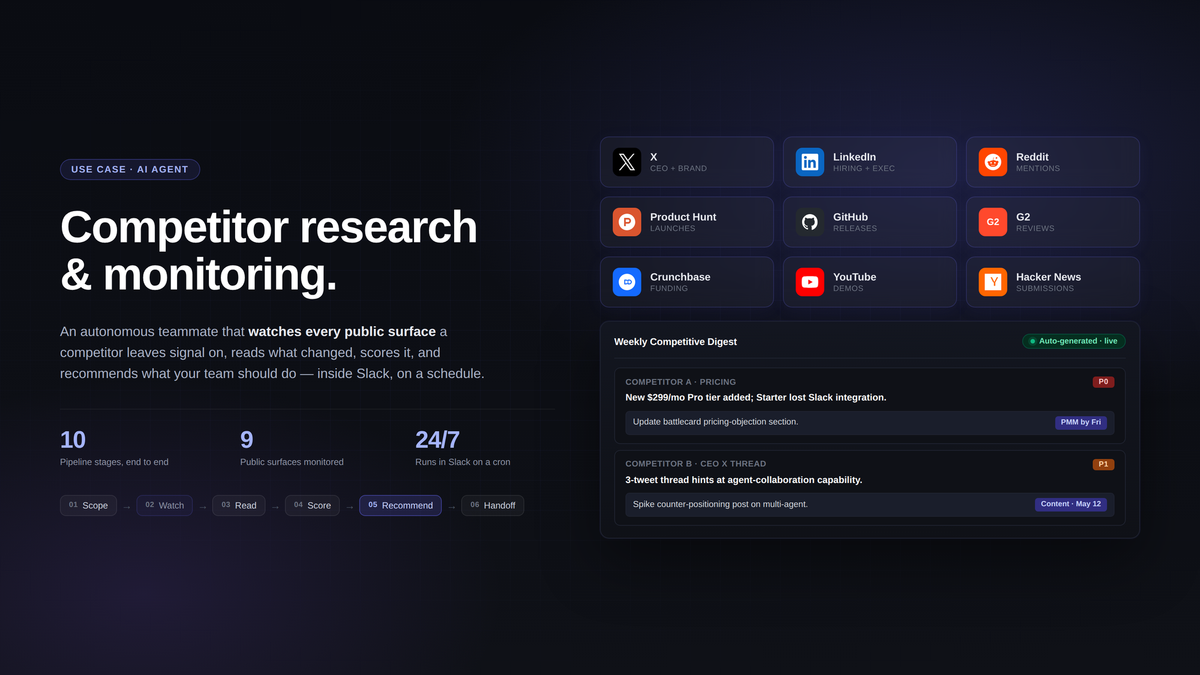
A competitor-research AI agent is an autonomous teammate that runs the full competitive-intelligence pipeline: monitoring competitor surfaces (web, social, hiring, reviews), reading what changed, scoring whether it matters, recommending what to do about it, handing off to the right person, and following up to close the loop. It works on a schedule, in the channels the team already lives in (Slack, email, the CRM), and remembers everything it has seen, so the next time someone asks "when did Competitor X last touch their pricing," the answer is a one-line query. The shorthand on Pazi's site for what these are is "AI teammates that work 24/7," and the framing that captures the difference between a teammate and a tool is whether the system takes real actions or just generates answers.
This is different from a competitive-intelligence tool or page-change monitor. Tools instrument surveillance and stop there: they watch a list of pages, fire alerts when something changes, and hand the rest of the job back to whoever has time. An agent runs the rest of the job: it reads the diff, scores it, drafts the response, hands off to the owner, and chases the open recommendations a week later when nothing has happened yet.
The full scope: a ten-stage job
Competitive intelligence has been recognized as a discipline for decades. The Strategic and Competitive Intelligence Professionals society (SCIP) codified the standard CI cycle as five stages: planning, collection, analysis, dissemination, and feedback. That's the academic frame. Operationally, in a modern software company, the scope is broader and more granular. The job runs as ten stages, because the team needs scoping that updates itself, surfaces that go far beyond the company website, and feedback loops that close inside Slack and the CRM rather than in a quarterly report nobody reads.
- Scoping — who we track, why, at what depth, on what cadence; a weekly auto-scan flags new entrants when their signal volume crosses a threshold, and the operator approves additions with a thumbs-up.
- Surveillance — every surface where competitors leave signal, with social and product launches weighted heavier than the standard "monitor pricing and the blog" tool default. Social is where roadmap leaks happen first; launch days are the most concentrated signal window in a quarter.
- Change detection — diffs classified against a learned ruleset: structural and substantive changes route forward, cosmetic and noise changes are logged but don't trigger the rest of the pipeline. Edge cases get surfaced for operator review rather than auto-classified.
- Reading the change — turning "pricing page changed" into "added a $299 Pro tier between Starter and Business, and Starter lost the Slack integration that used to be included." This is the stage CI tools can't do. Every flagged change gets a structured read-out: what changed, what it means, what category, what cascades to expect next.
- Scoring — operator-configured rubric per axis (pricing, positioning, roadmap, GTM, organizational), with severity triggers the team sets. Overrides are one-line and logged; the agent tightens the rubric over the next month from the override pattern.
- Recommendation — a card with the named owner, the deadline (default five days for P0, two weeks for P1, end of quarter for P2), the source links, and a draft of the artifact where applicable: a battlecard diff, a counter-post outline, an objection script.
- Handoff — posted in the owner's channel, not a CI channel. If the owner is another colleague-agent, the call is a structured agent-to-agent handoff with state tracking (waiting, acknowledged, in progress, done) so nothing falls through.
- Reporting — weekly digest, monthly trend rollup, quarterly landscape, all on cron, each delivered as a PDF with a minimal Slack thread summary. The quarterly is the only one where the agent flags itself as needing operator authoring on the strategic-recommendation section.
- Loop close — daily pass over past-due handoffs, one chase per missed date in the owner's channel, weekly escalation on unactioned P0s. Operators mark a recommendation "won't do" with one click and the agent removes it from the chase queue.
- Memory — every change, read-out, score, recommendation, handoff state, override, and loop-close outcome persisted per competitor, queryable from any Slack channel the Growth agent is in. Memory is read-mostly; historical edits require explicit operator instruction.
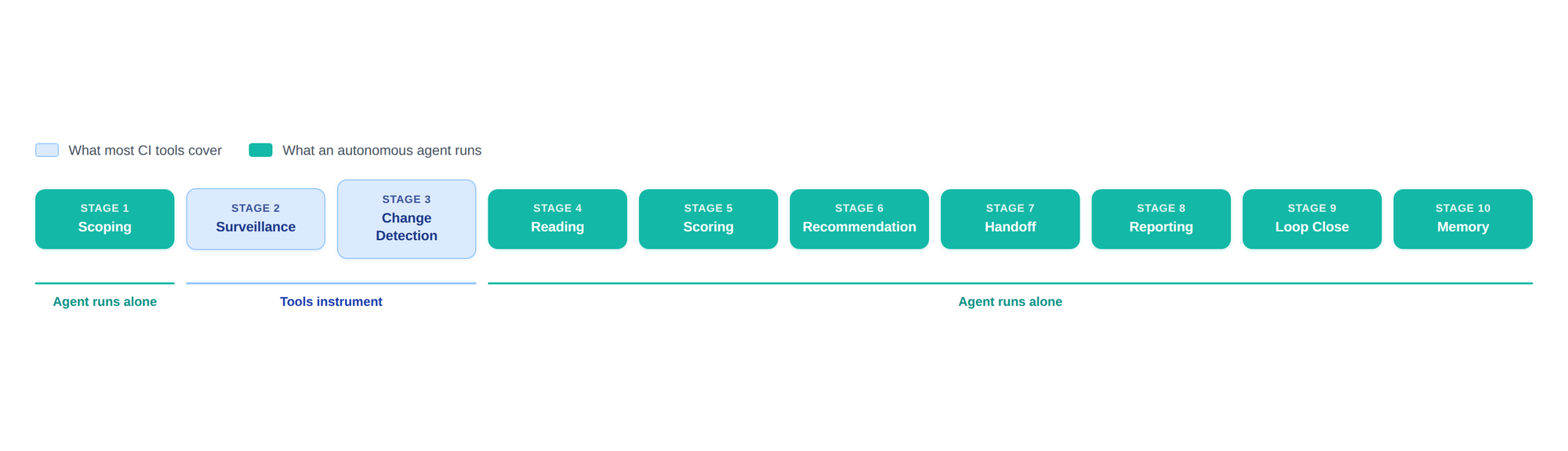
Most CI tooling automates stages 2 and 3 (surveillance and change detection) and stops there. The platform fires "this page changed" alerts and the operator is on the hook for the other eight stages, including the messy ones (reading, scoring, recommending) and the unglamorous ones (handoff, loop close, memory). That's the gap. Surveillance is the easy third of the job and the part everyone instruments; the hard two-thirds runs on whoever has the time, which usually means it doesn't run.
The maturity gap shows up in the data. There's been a 125% increase since 2018 in CI programs that operate against KPIs, and companies using conversational intelligence tools for compete are seeing 82% lifts in sales effectiveness. Tooling helps and the discipline is maturing, but in practice most CI programs still stop at the alert and the pipeline beyond stage 3 stays manual.
Types of competitor-research agents
Glossary articles in this category split competitor-research agents into specialized types: news and signal trackers, pricing and product agents, hiring signal agents, sentiment and review monitors, sales battlecard builders, market share and benchmarking agents. That split makes sense for tool-shaped products that build one type and ship it. For a multi-purpose Growth agent, those are jobs the same agent runs against one per-competitor record, scored on one rubric, surfaced in one Slack channel. Six tools means six dashboards and six places the loop fails; one agent means one place. The value of CI is in the cross-cutting view, where this pricing change plus that hiring pattern plus that exec post adds up to a category move, and that view only emerges when one system holds all the inputs against one memory.
What changes when the pipeline actually runs
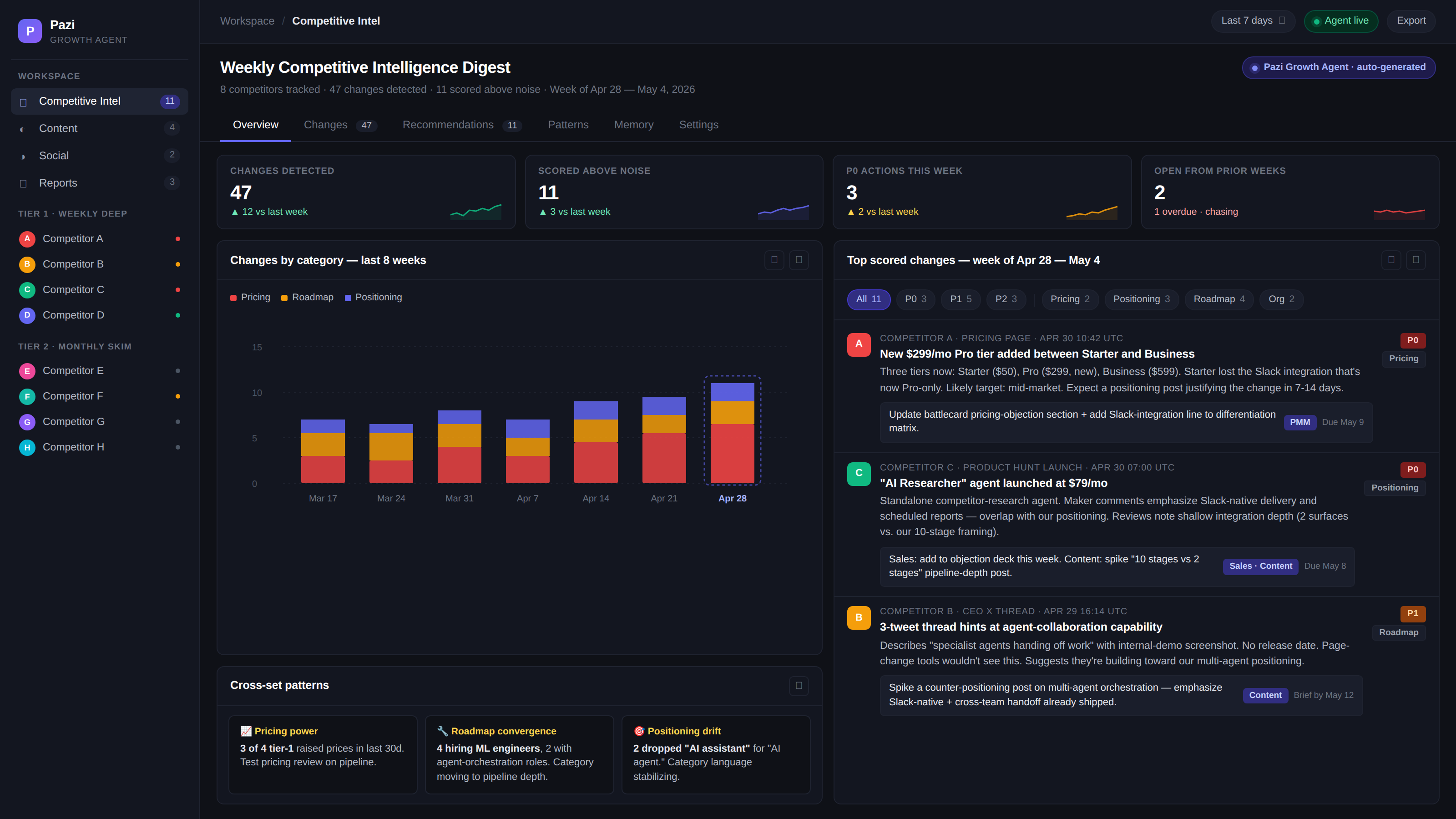
When all ten stages run autonomously instead of just two and three, the cadence of the team changes. Strategy iteration moves from quarterly to weekly because the team gets named recommendations in a digest, not stale alerts. Sales enablement stays current because the agent hands off on every scored change, rather than waiting for someone to schedule a battlecard refresh. Patterns emerge across the set: three tier-1 competitors raising prices in a month is a pricing-power signal, four hiring ML engineers is a category-roadmap signal, and those patterns are only visible because one system holds the whole history against one rubric. Blind spots shrink because new entrants get auto-flagged when their signal volume crosses the threshold, not when a customer churns to one. And feedback loops actually close, because every handed-off action has a due date and a chase.
Challenges and considerations
An agent running autonomously isn't plug-and-play. Some surfaces are gated and have to be wired in by the operator with appropriate credentials or authorized exports; the agent runs whatever inputs it's been authorized to run, not whatever the team wishes it had. Default scoring is a starting point, not the finished rubric: most teams need two or three weeks of operator overrides for the agent to settle into the team's actual priorities. Trust calibration takes time too, but the agent ships every recommendation with the source links, the read-out, and the rationale, which makes earning trust easier than it would be from a black box. The tradeoff is real: an agent removes about 80% of the manual CI work (stages 1, 4, 5, 6, 7, 8, 9, and 10) but the operator still owns the strategic calls and the configuration. The agent doesn't replace the CI lead; it removes the work that was preventing the CI lead from doing the strategic part of the job.
Getting started with Pazi for competitive intelligence
Five concrete steps a team can take this week.
First, define what you want to know: pricing changes, roadmap signals, customer-sentiment shifts, hiring patterns. Pick the two or three axes that matter most for the team's strategic priorities. The scoring rubric and the surveillance configuration both flow from this.
Second, pick a prebuilt agent or Build Your Own. The Pazi Growth agent ships with competitive research as a named job, described on the site as "AI growth agent that researches competitors, creates content, manages social media, and drives marketing strategy," with a default rubric that works for most software teams. If the category needs a specific scoring model, surface mix, or tier system, Build Your Own lets the operator spec the agent against their own playbook.
Third, wire your surfaces. List the competitor URLs and surfaces the team wants monitored: pricing pages, blogs, changelogs, jobs pages, key social accounts, review sites. The agent ingests these into stage 2 surveillance once and runs them on cadence.
Fourth, set the scoring rubric. Configure the axes (pricing, positioning, roadmap, GTM, organizational) and the severity triggers. Defaults work; expect to tune them in the first two or three weeks as the agent learns from the team's overrides.
Fifth, deploy in Slack. The agent posts to the channel where the team already decides. Recommendations land where the conversation happens. No new dashboard.
Build the agent
The Pazi Growth agent runs this pipeline today. For teams whose CI work doesn't fit a default rubric, Build Your Own lets you spec the scoring, the surfaces, and the handoff rules against how your team actually decides. The agent works inside Slack, runs on a cron, and doesn't add another dashboard to log into.



